Analysis Of Variance (ANOVA)
An ANOVA is for testing the equality of several means simultaneously. A single quantitative response variable is required with one or more qualitative explanatory variables, i.e., factors.
One-way ANOVA
Each experimental unit is assigned to exactly one factor-level combination. Another way to say this is “one measurement per individual” (no repeated measures) and “equal numbers of individuals per group”.
Overview
An ANOVA is only appropriate when all of the following are satisfied.
The sample(s) of data can be considered to be representative of their population(s).
The data is normally distributed in each group. (This can safely be assumed to be satisfied when the residuals from the ANOVA are normally distributed.)
The population variance of each group can be assumed to be the same. (This can be safely assumed to be satisfied when the residuals from the ANOVA show constant variance, i.e., are similarly spread out.)
Hypotheses
For a One-way ANOVA
\[ H_0: \alpha_1 = \alpha_2 = \ldots = 0 \] \[ H_a: \alpha_i \neq 0 \ \text{for at least one} \ i \]
Mathematical Model
A typical model for a one-way ANOVA is of the form \[ Y_{ij} = \mu + \alpha_i + \epsilon_{ij} \] where \(\mu\) is the grand mean, \(\alpha_i\) is a factor with at least two levels, and \(\epsilon_{ijk} \sim N(0,\sigma^2)\) is the error term.
R Instructions
Console Help Command: ?aov()
myaov <- aov(y ~ A, data=YourDataSet) Perform the ANOVA
summary(myaov) View the ANOVA Results
plot(myaov, which=1:2) Check ANOVA Assumptions
myaovis some name you come up with to store the results of theaov()test.ymust be a “numeric” vector of the quantitative response variable.Ais a qualitative variable (should haveclass(A)equal tofactororcharacter. If it does not, useas.factor(A)inside theaov()command.YourDataSetis the name of your data set.
Example Code
Hover your mouse over the example codes to learn more.
chick.aov <- Saves the results of the ANOVA test as an object named ‘chick.aov’. aov( ‘aov()’ is a function in R used to perform the ANOVA. weight ‘weight’ is a numeric variable from the chickwts dataset. ~ ‘~’ is the tilde symbol used to separate the left- and right-hand side in a model formula. feed, ‘feed’ is a qualitative variable in the chickwts dataset. data = chickwts) ‘chickwts’ is a dataset in R.
summary( ‘summary()’ shows the results of the ANOVA. chick.aov) ‘chick.aov’ is the name of the ANOVA.
Press Enter to run the code if you have typed it in yourself. You can also click here to view the output. Click to View Output Click to View Output.
par( ‘par’ is a R function that can be used to set or query graphical parameters. mfrow = c(1,2)) Parameter is being set. The first item inside the combine function c() is the number of rows and the second is the number of columns.
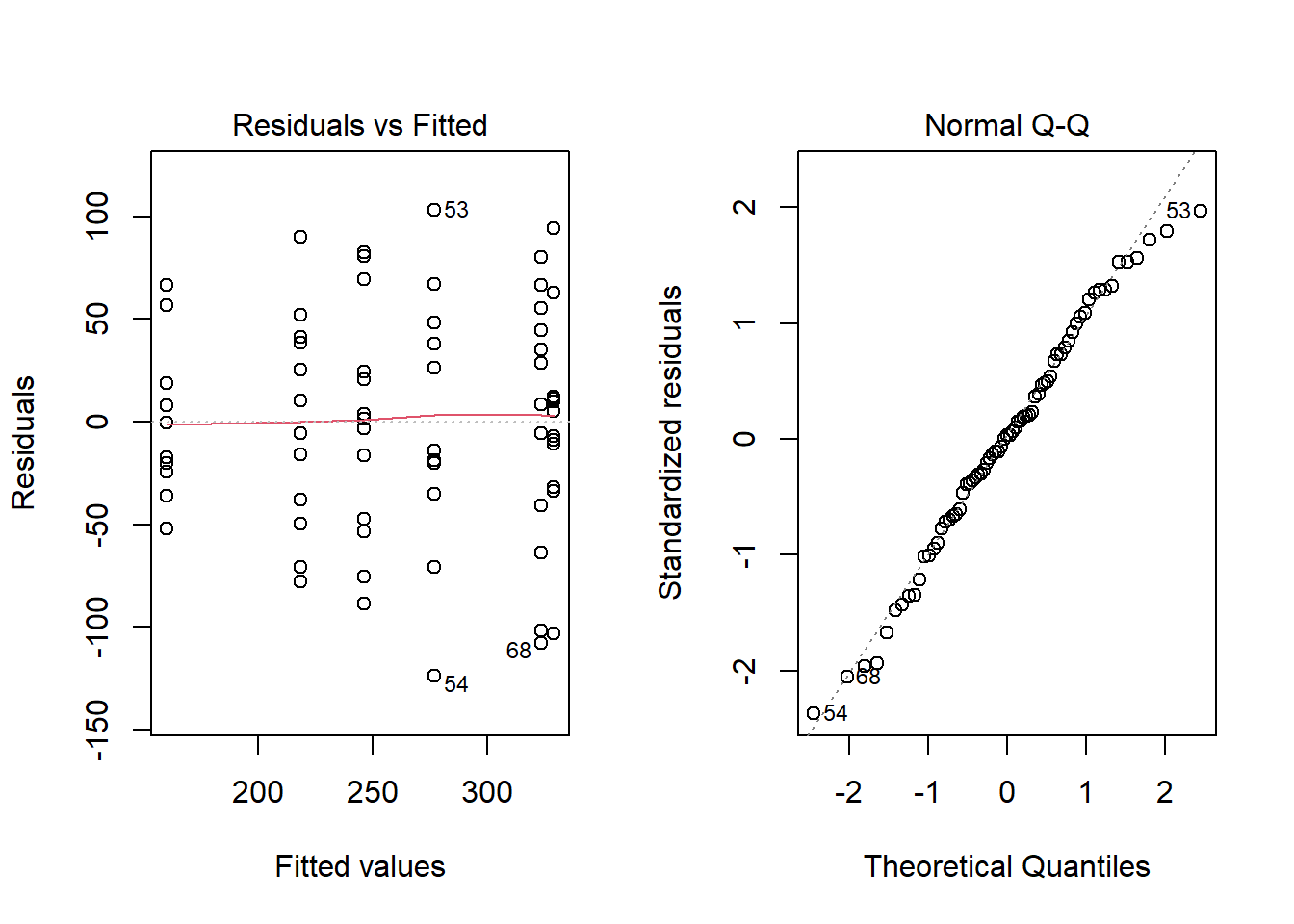
plot( ‘plot’ is a R function for the plotting of R objects. chick.aov, ‘chick.aov’ is the name of the ANOVA. which = 1:2) Will show the Residuals vs Fitted and the Normal QQ-plot to check the ANOVA assumptions. Click to View Output Click to View Output.
Explanation
Analysis of variance (ANOVA) is often applied to the scenario of testing for the equality of three or more means from (possibly) separate normal distributions of data. The normality assumption is required. No matter the sample size. If the distributions are skewed then a nonparametric test should be applied instead of ANOVA.
One-Way ANOVA
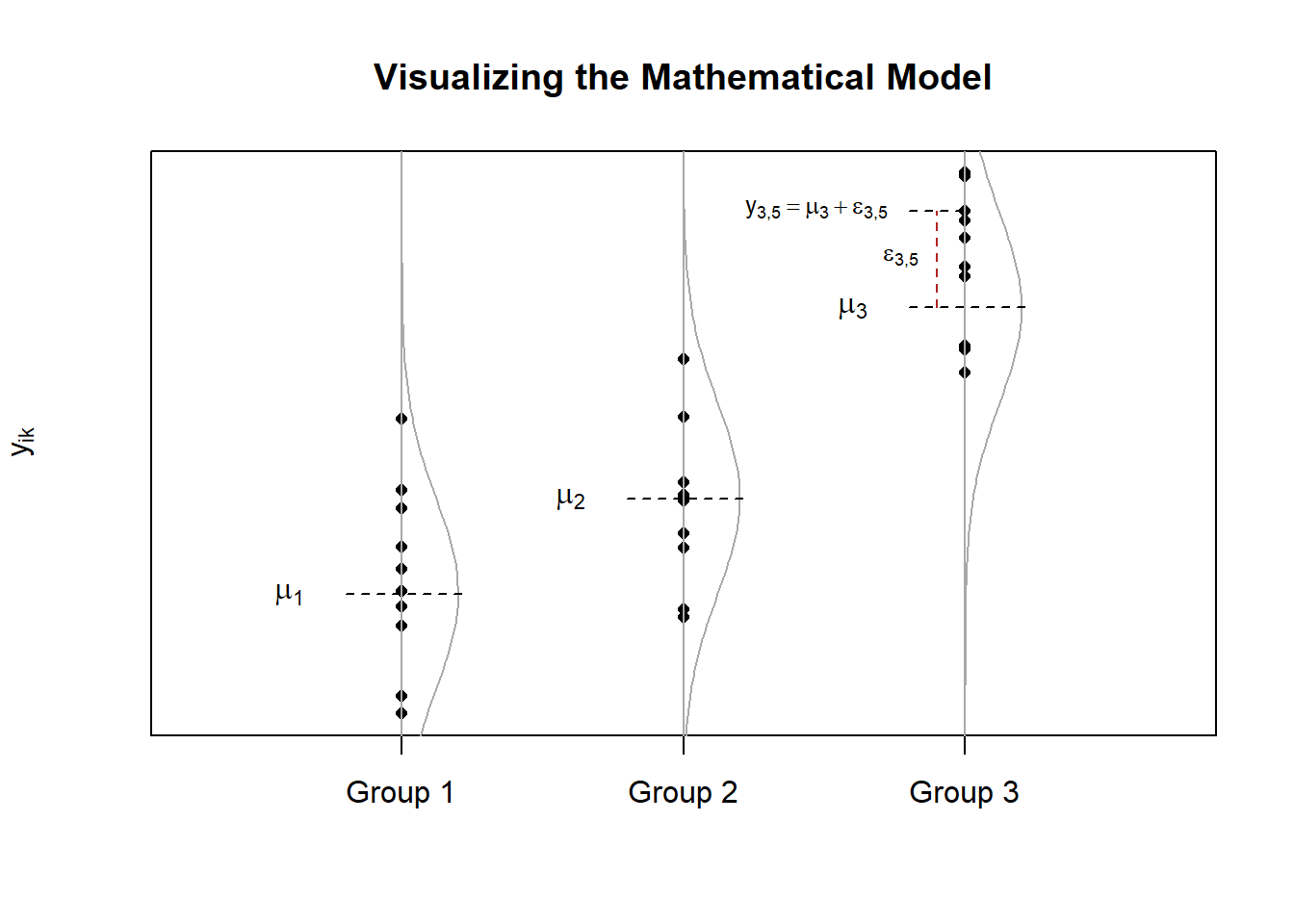
One-way ANOVA is when a completely randomized design is used with a single factor of interest. A typical mathematical model for a one-way ANOVA is of the form \[ Y_{ik} = \mu_i + \epsilon_{ik} \quad (\text{sometimes written}\ Y_{ik} = \mu + \alpha_i + \epsilon_{ik}) \] where \(\mu_i\) is the mean of each group (or level) \(i\) of a factor, and \(\epsilon_{ik}\sim N(0,\sigma^2)\) is the error term. The plot below demonstrates what these symbols represent. Note that the notation \(\epsilon_{ik}\sim N(0,\sigma^2)\) states that we are assuming the error term \(\epsilon_{ik}\) is normally distributed with a mean of 0 and a standard deviation of \(\sigma\).
Hypotheses
The aim of ANOVA is to determine which hypothesis is more plausible, that the means of the different distributions are all equal (the null), or that at least one group mean differs (the alternative). Mathematically, \[ H_0: \mu_1 = \mu_2 = \ldots = \mu_m = \mu \] \[ H_a: \mu_i \neq \mu \quad \text{for at least one}\ i\in\{1,\ldots,m\}. \] In other words, the goal is to determine if it is more plausible that each of the \(m\) different samples (where each sample is of size \(n\)) came from the same normal distribution (this is what the null hypothesis claims) or that at least one of the samples (and possibly several or all) come from different normal distributions (this is what the alternative hypothesis claims).
Visualizing the Hypotheses
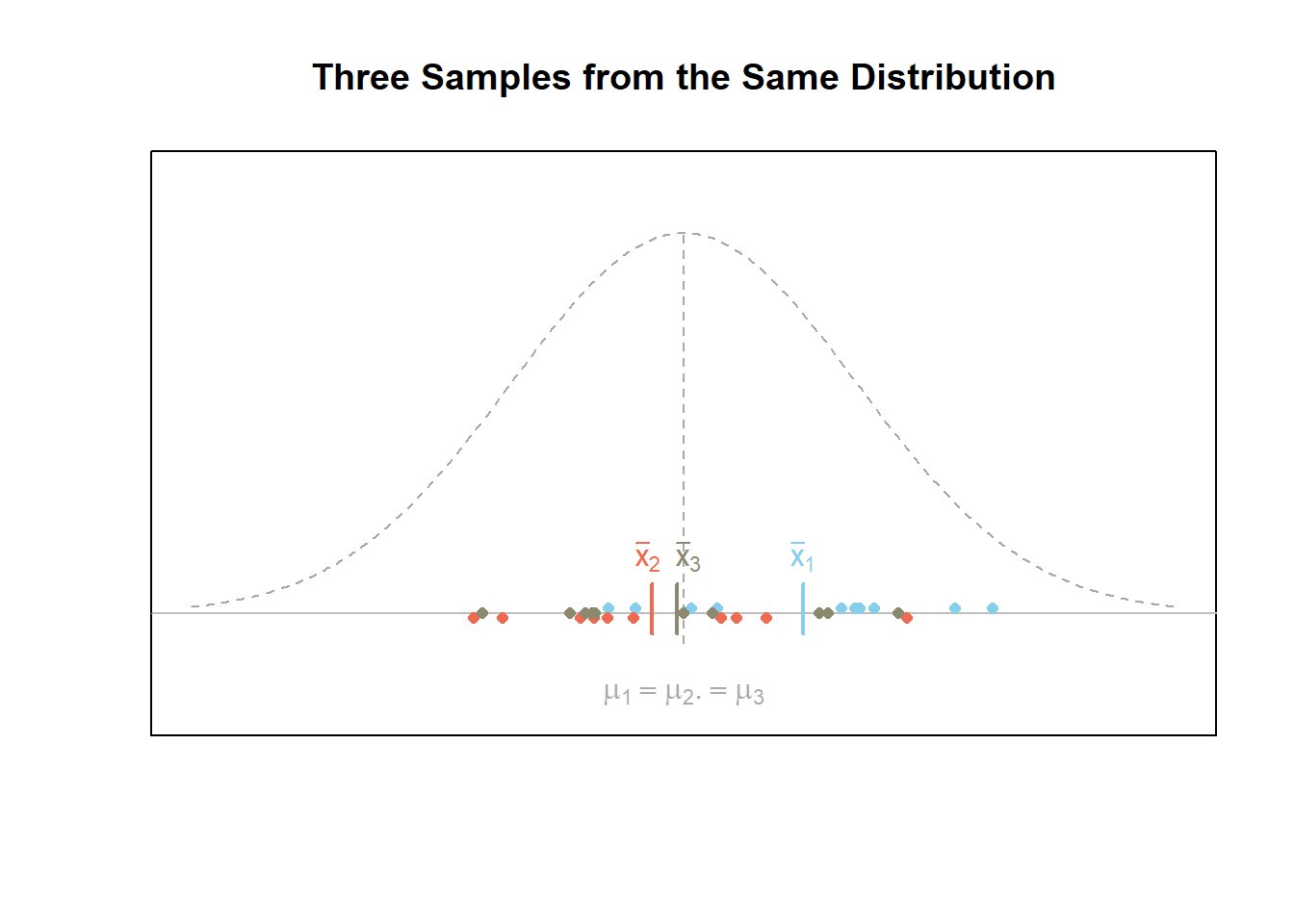
The first figure below demonstrates what a given scenario might look like when all \(m=3\) samples of data are from the same normal distribution. In this case, the null hypothesis \(H_0\) is true. Notice that the variability of the sample means is smaller than the variability of the points.
The figure below shows what a given scenario might look like for \(m=3\) samples of data from three different normal distributions. In this case, the alternative hypothesis \(H_a\) is true. Notice that the variability of the sample means, i.e., \((\bar{x}_1,\bar{x}_2,\bar{x}_3)\), is greater than the variability of the points.
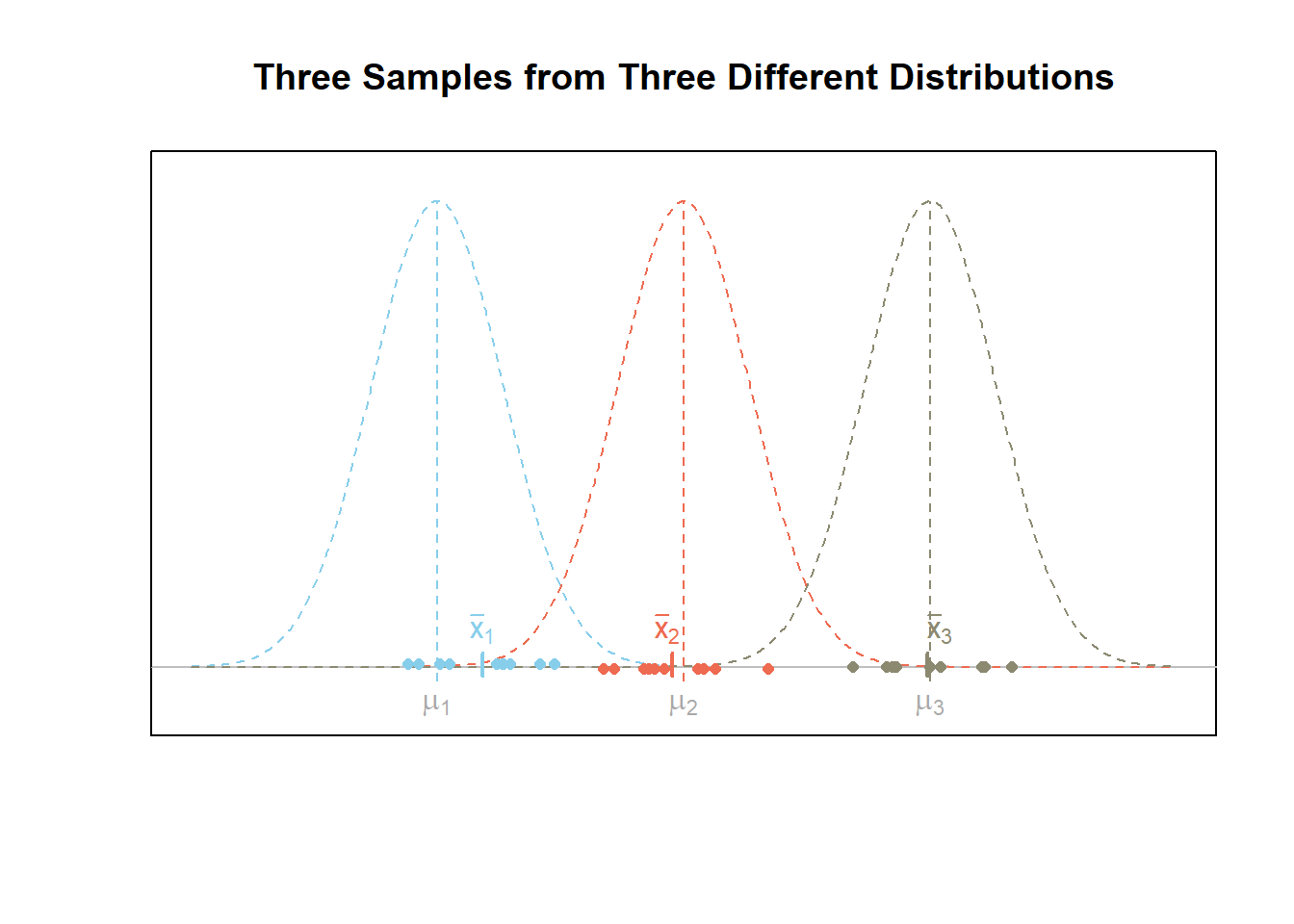
Explaining the Name
The above plots are useful in understanding the mathematical details behind ANOVA and why it is called analysis of variance. Recall that variance is a measure of the spread of data. When data is very spread out, the variance is large. When the data is close together, the variance is small. ANOVA utilizes two important variances, the between groups variance and the within groups variance.
Between groups variance–a measure of the variability in the sample means, the \(\bar{x}\)’s.
Within groups variance–a combined measure of the variability of the points within each sample.
The plot below combines the information from the previous plots for ease of reference. It emphasizes the fact that when the null hypothesis is true, the points should have a large variance (be really spread out) while the sample means are relatively close together. On the other hand, when the points are relative close together within each sample and the sample means have a large variance (are really spread out) then the alternative hypothesis is true. This is the theory behind analysis of variance, or ANOVA.

Calculating the Test Statistic, \(F\)
The ratio of the “between groups variation” to the “within groups variation” provides the test statistic for ANOVA. Note that the test statistic of ANOVA is an \(F\) statistic.
\[ F = \frac{\text{Between groups variation}}{\text{Within groups variation}} \]
It would be good to take a minute and review the \(F\) distribution. The \(p\)-value for ANOVA thus comes from an \(F\) distribution with parameters \(p_1 = m-1\) and \(p_2 = n-m\) where \(m\) is the number of samples and \(n\) is the total number of data points.
A Deeper Look at Variance
It is useful to take a few minutes and explain the word variance as well as mathematically define the terms “within group variance” and “between groups variance.”
Variance is a statistical measure of the variability in data. The square root of the variance is called the standard deviation and is by far the more typical measure of spread. This is because standard deviation is easier to interpret. However, mathematically speaking, the variance is the more important measurement.
As mentioned previously, the variance turns out to be the key to determining which hypothesis is the most plausible, \(H_0\) or \(H_a\), when several means are under consideration. There are two variances that are important for ANOVA, the “within groups variance” and the “between groups variance.”
Recall that the formula for computing a sample variance is given by \[ s^2 = \frac{\sum_{i=1}^n(x_i - \bar{x})^2}{n-1} \quad\leftarrow \frac{\text{sum of squares}}{\text{degrees of freedom}} \] This formula has a couple of important pieces that are so important they have been given special names. The \(n-1\) in the denominator of the formula is called the “degrees of freedom.” The other important part of this formula is the \(\sum_{i=1}^n(x_i - \bar{x})^2\), which is called the “sum of squared errors” or sometimes just the “sum of squares” or “SS” for short. Thus, the sample variance is calculated by computing a “sum of squares” and dividing this by the “degrees of freedom.”
It turns out that this general approach works for many different contexts. Specifically, it allows us to compute the “within groups variance” and the “between groups variance.” To introduce the mathematical definitions of these two variances, we need to introduce some new notation.
Let \(\bar{y}_{i\bullet}\) represent the sample mean of group \(i\) for \(i=1,\ldots,m\).
Let \(n_i\) denote the sample size in group \(i\).
Let \(\bar{y}_{\bullet\bullet}\) represent the sample mean of all \(n = n_1+n_2+\cdots+n_m\) data points.
The mathematical calculations for each of these variances is given as follows. \[ \text{Between groups variance} = \frac{\sum_{i=1}^m (\bar{y}_{i\bullet}-\bar{y}_{\bullet\bullet})^2}{m-1} \leftarrow \frac{\text{Between groups sum of squares}}{\text{Between groups degrees of freedom}} \] \[ \text{Within groups variance} = \frac{\sum_{i=1}^m\sum_{k=1}^{n_i}(y_{ik}-\bar{y}_{i\bullet})^2}{n-m} \leftarrow \frac{\text{Within groups sum of squares}}{\text{Within groups degrees of freedom}} \]
A Fabricated Example
The following table provides three samples of data: A, B, and C. These samples were randomly generated from normal distributions using a computer. The true means \(\mu_1, \mu_2\), and \(\mu_3\) of the normal distributions are thus known, but withheld from you at this point of the example.
| A | B | C |
|---|---|---|
| 13.15457 | 13.17463 | 16.66831 |
| 12.65225 | 12.16277 | 15.54719 |
| 13.73061 | 12.76905 | 16.63074 |
| 14.43471 | 13.38524 | 15.06726 |
| 13.79728 | 12.02690 | 15.57534 |
| 13.88599 | 13.24651 | 15.99915 |
| 12.77753 | 12.58386 | 15.58995 |
| 13.81536 | 12.64615 | 16.99429 |
| 13.03635 | 12.52055 | 15.47153 |
| 14.26062 | 14.03566 | 16.13330 |
An ANOVA will be performed with the sample data to determine which hypothesis is more plausible: \[ H_0: \mu_1 = \mu_2 = \mu_3 = \mu \] \[ H_a: \mu_i \neq \mu \ \text{for at least one} \ i \in \{1,\ldots,m\} \]
To perform an ANOVA, we must compute the between groups variance and the within groups variance. This requires the Between groups sums of squares, within groups sums of squares, between groups degrees of freedom, and the within groups degrees of freedom. Note that to get the sums of squares, we first had to calculate \(\bar{y}_{1\bullet}\), \(\bar{y}_{2\bullet}\), \(\bar{y}_{3\bullet}\), and \(\bar{y}_{\bullet\bullet}\) where the 1, 2, 3 corresponds to Samples A, B, and C, respectively. After some work, we find these values to be \[ \bar{y}_{1\bullet} = 13.55, \quad \bar{y}_{2\bullet} = 12.86 \quad \bar{y}_{3\bullet} = 15.97 \] and \[ \bar{y}_{\bullet\bullet} = \frac{13.55+12.86+15.97}{3} = 14.13 \] Using these values we can then compute the between groups sum of squares and the within groups sum of squares according to the formulas stated previously. This process is very tedious and will not be demonstrated. Only the results are shown in the following table which summarizes all the important information.
| Degrees of Freedom | Sum of Squares | Variance | F-value | p-value | |
|---|---|---|---|---|---|
| Between groups | 2 | 53.3 | 26.67 | 70.2 | 2e-11 |
| Within groups | 27 | 10.3 | 0.38 |
ANOVA Table
In general, the ANOVA table is created by
| Degrees of Freedom | Sum of Squares | Variance | F-value | p-value | |
|---|---|---|---|---|---|
| Between groups | \(m-1\) | \(\sum_{i=1}^m n_i(\bar{y}_{i\bullet}-\bar{y}_{\bullet\bullet})^2\) | \(\frac{\text{sum of squares}}{\text{degrees of freedom}}\) | \(\frac{\text{Between groups variance}}{\text{Within groups variance}}\) | \(F\)-distribution tail probability |
| Within groups | \(n-m\) | \(\sum_{i=1}^m\sum_{k=1}^{n_i}(y_{ik}-\bar{y}_{i\bullet})^2\) | \(\frac{\text{sum of squares}}{\text{degrees of freedom}}\) |
ANOVA Assumptions
The requirements for an analysis of variance (the assumptions of the test) are two-fold and concern only the error terms, the \(\epsilon_{ik}\).
The errors are normally distributed.
The variance of the errors is constant.
Both of these assumptions were stated in the mathematical model where we assumed that \(\epsilon_{ik}\sim N(0,\sigma^2)\).
Checking ANOVA Assumptions
To check that the ANOVA assumptions are satisfied, it is required to check the data in each group for normality using QQ-Plots. Also, the sample variance of each group must be relatively constant. The fastest way to check these two assumptions is by analyzing the residuals.
- An ANOVA residual is defined as the difference between the observed value of \(y_{ik}\) and the mean \(\bar{y}_{i\bullet}\). Mathematically, \[ r_{ik} = y_{ik} - \bar{y}_{i\bullet} \] One QQ-Plot of the residuals will provide the necessary evidence to decide if it is reasonable to assume that the error terms are normally distributed. Also, the constant variance can be checked visually by using what is known as a residuals versus fitted values plot. For the Fabricated Example above, the QQ-Plot and residuals versus fitted values plots show the two assumptions of ANOVA appear to be satisfied.
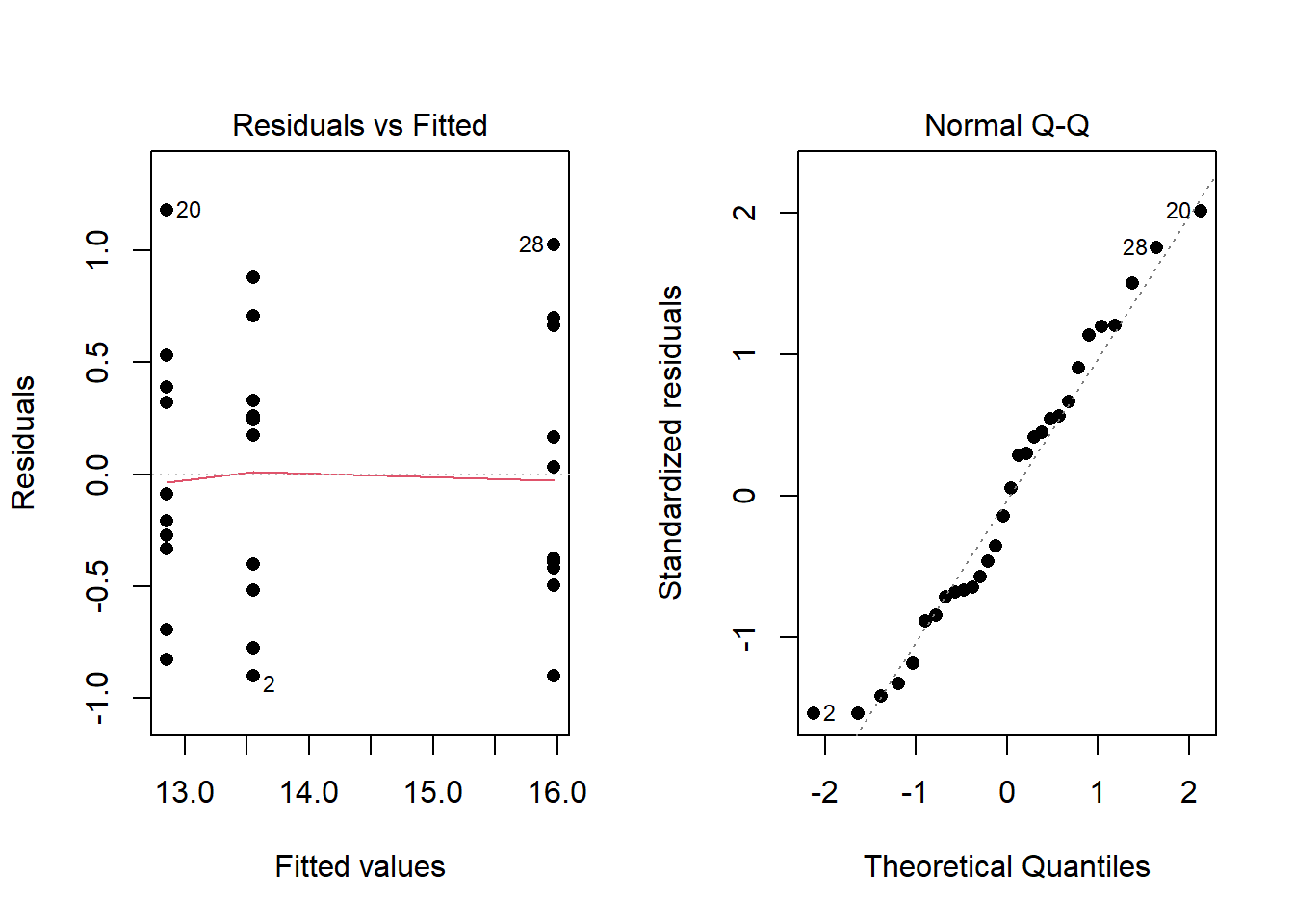
Examples: chickwts (One-way)
Two-way ANOVA
Overview
Hypotheses
With a two-way ANOVA there are three sets of hypotheses.
One for the first factor: \[ H_0: \alpha_1 = \alpha_2 = \ldots = 0 \] \[ H_a: \alpha_i \neq 0 \ \text{for at least one} \ i \]
One for the second factor: \[ H_0: \beta_1 = \beta_2 = \ldots = 0 \] \[ H_a: \beta_j \neq 0 \ \text{for at least one} \ j \]
One for the interaction of the two factors: \[ H_0: \text{The effect of} \ \alpha \ \text{is the same for all levels of} \ \beta \] \[ H_a: \text{The effect of} \ \alpha \ \text{is different for at least one level of} \ \beta \]
Mathematical Model
\[ Y_{ijk} = \mu + \alpha_i + \beta_j + \alpha\beta_{ij} + \epsilon_{ijk} \] where \(\mu\) is the grand mean, \(\alpha_i\) is one factor with at least two levels, \(\beta_j\) is another factor with at least two levels, \(\alpha\beta_{ij}\) is the interaction of the two factors, and \(\epsilon_{ijk} \sim N(0,\sigma^2)\) is the error term.
Note that more than two factors are allowed, i.e., more than \(\alpha_i\) and \(\beta_j\), and is sometimes called three-way ANOVA, four-way ANOVA, and so on. It is not required to include interaction terms, like \(\alpha\beta_{ij}\). The error term \(\epsilon\) is always required.
R Instructions
Console Help Command: ?aov()
myaov <- aov(y ~ A+B+A:B, data=YourDataSet) Perform the ANOVA
summary(myaov) View the ANOVA Results
plot(myaov, which=1:2) Check ANOVA assumptions
myaovis some name you come up with to store the results of theaov()test.ymust be a “numeric” vector of the quantitative response variable.Ais a qualitative variable (should haveclass(A)equal tofactororcharacter. If it does not, useas.factor(A)inside theaov()command.Bis a second qualitative variable that should also be either afactoror acharactervector.- Note that factors
C,D, and so on could also be added+to the model if desired. A:Bdenotes the interaction of the factorsAandB. It is not required and should only be included if the interaction term is of interest.YourDataSetis the name of your data set.
Example Code
Hover your mouse over the example codes to learn more.
warp.aov <- Saves the results of the ANOVA test as an object named ‘warp.aov’. aov( ‘aov()’ is a function in R used to perform the ANOVA. breaks ‘breaks’ is a numeric variable from the warpbreaks dataset. ~ ‘~’ is the tilde symbol used to separate the left- and right-hand side in a model formula. wool ‘wool’ is a qualitative variable in the warpbreaks dataset. + tension ‘tension’ is another qualitative variable in the warpbreaks dataset. + wool:tension, The interaction of wool and tension. data = warpbreaks) ‘warpbreaks’ is a dataset in R.
summary( ‘summary()’ shows the results of the ANOVA. warp.aov) ‘warp.aov’ is the name of the ANOVA.
Press Enter to run the code if you have typed it in yourself. You can also click here to view the output. Click to View Output Click to View Output.
par( ‘par’ is a R function that can be used to set or query graphical parameters. mfrow = c(1,2)) Parameter is being set. The first item inside the combine function c() is the number of rows and the second is the number of columns.
plot( ‘plot’ is a R function for the plotting of R objects. warp.aov, ‘warp.aov’ is the name of the ANOVA. which = 1:2) Will show the Residuals vs Fitted and the Normal QQ-plot to check the ANOVA assumptions. Click to View Output Click to View Output.
Explanation
Hypotheses in Two-way ANOVA
The hypotheses that can be tested in a two-way ANOVA that includes an interaction term are three-fold.
Hypotheses about \(\alpha\) where \(\alpha\) has \(m\) levels. \[ H_0: \alpha_1 = \alpha_2 = \ldots = \alpha_m = 0 \] \[ H_a: \alpha_i \neq 0\ \text{for at least one}\ i\in\{1,\ldots,m\} \]
Hypotheses about \(\beta\) where \(\beta\) has \(q\) levels. \[ H_0: \beta_1 = \beta_2 = \ldots = \beta_q = 0 \] \[ H_a: \beta_j \neq 0\ \text{for at least one}\ i\in\{1,\ldots,q\} \]
Hypotheses about the interaction term \(\alpha\beta\). \[ H_0: \text{the effect of one factor is the same across all levels of the other factor} \] \[ H_a: \text{the effect of one factor differs for at least one level of the other factor} \]
Expanding the ANOVA Model
It turns out that more can be done with ANOVA than simply checking to see if the means of several groups differ. Reconsider the mathematical model of two-way ANOVA. \[ Y_{ijk} = \mu + \alpha_i + \beta_j + \alpha\beta_{ij} + \epsilon_{ijk} \] This model could be expanded to include any number of new terms in the model. The power of this approach is in the several questions (hypotheses) that can be posed to data simultaneously.
Examples: warpbreaks (Two-way), Class Activity (Two-way), CO2 (three-way)
Block Design
Repeated measures or other factors that group individuals into similar groups (blocks) are included in the study design.
Overview
A typical model for a block design is of the form \[ Y_{lijk} = \mu + B_l + \alpha_i + \beta_j + \alpha\beta_{ij} + \epsilon_{ijlk} \] where \(\mu\) is the grand mean, \(B_l\) is the blocking factor, \(\alpha_i\) is one factor with at least two levels, \(\beta_j\) is another factor with at least two levels, \(\alpha\beta_{ij}\) is the interaction of the two factors, and \(\epsilon_{ijlk} \sim N(0,\sigma^2)\) is the error term.
Only one block and one factor is required. Multiple blocks and multiple factors are allowed. It is not required to include interaction terms. The error term is always required.
R Instructions
Console Help Command: ?aov()
myaov <- aov(y ~ Block+A+B+A:B, data=YourDataSet) Perform the test
summary(myaov) View the ANOVA Results
plot(myaov, which=1:2) Check ANOVA assumptions
myaovis some name you come up with to store the results of theaov()test.ymust be a “numeric” vector of the quantitative response variable.Blockis a qualitative variable that is not of direct interest, but is included in the model to account for variability in the data. It should haveclass(Block)equal to either factor or character. Useas.factor()if it does not.Ais a qualitative variable (should haveclass(A)equal tofactororcharacter. If it does not, useas.factor(A)inside theaov()command.Bis a second qualitative variable that should also be either afactoror acharactervector. If it does not, useas.factor(B).- Note that factors
C,D, and so on could also be added+to the model if desired. A:Bdenotes the interaction of the factorsAandB. It is not required and should only be included if the interaction term is of interest.YourDataSetis the name of your data set.
Examples: ChickWeight