Study Guide
Math 325
General Concepts
In general, you should be able to:
- Identify the appropriate test that should be used for a given scenario.
- Perform the appropriate test and create supporting graphics and numerical summaries in R.
- Recognize the four basic parametric distributions (normal, t, chi-squared, F) along with their parameters.
- Recognize the logic behind each nonparametric test.
- State the definition of a p-value.
- Identify the two things needed to obtain a p-value.
- Recognize when it is appropriate to make inference and when it is appropriate to just describe data.
Weeks 1 & 2: R Intro & Descriptive Statistics
Overview
You should be able to:
- State the various types, proper usages, and proper interpretations of numerical and graphical summaries.
- Use R to compute numerical and graphical summaries for a given dataset.
- Perform basic data manipulations in R with
subset(),[ , ], and$.
Describing Data with R
Question 1
Use the Utilities dataset in RStudio, which records monthly utility costs and details for a certain residence, to create an appropriate graphic of monthly gas bill costs.
Be sure library(mosaic) is loaded.
Also, these commands may be useful.
Based on what you find in your graphic, which statistic would be most meaningful for describing the typical cost of the monthly gas bill for this residence?
The three main choices of graphic for this question would be:
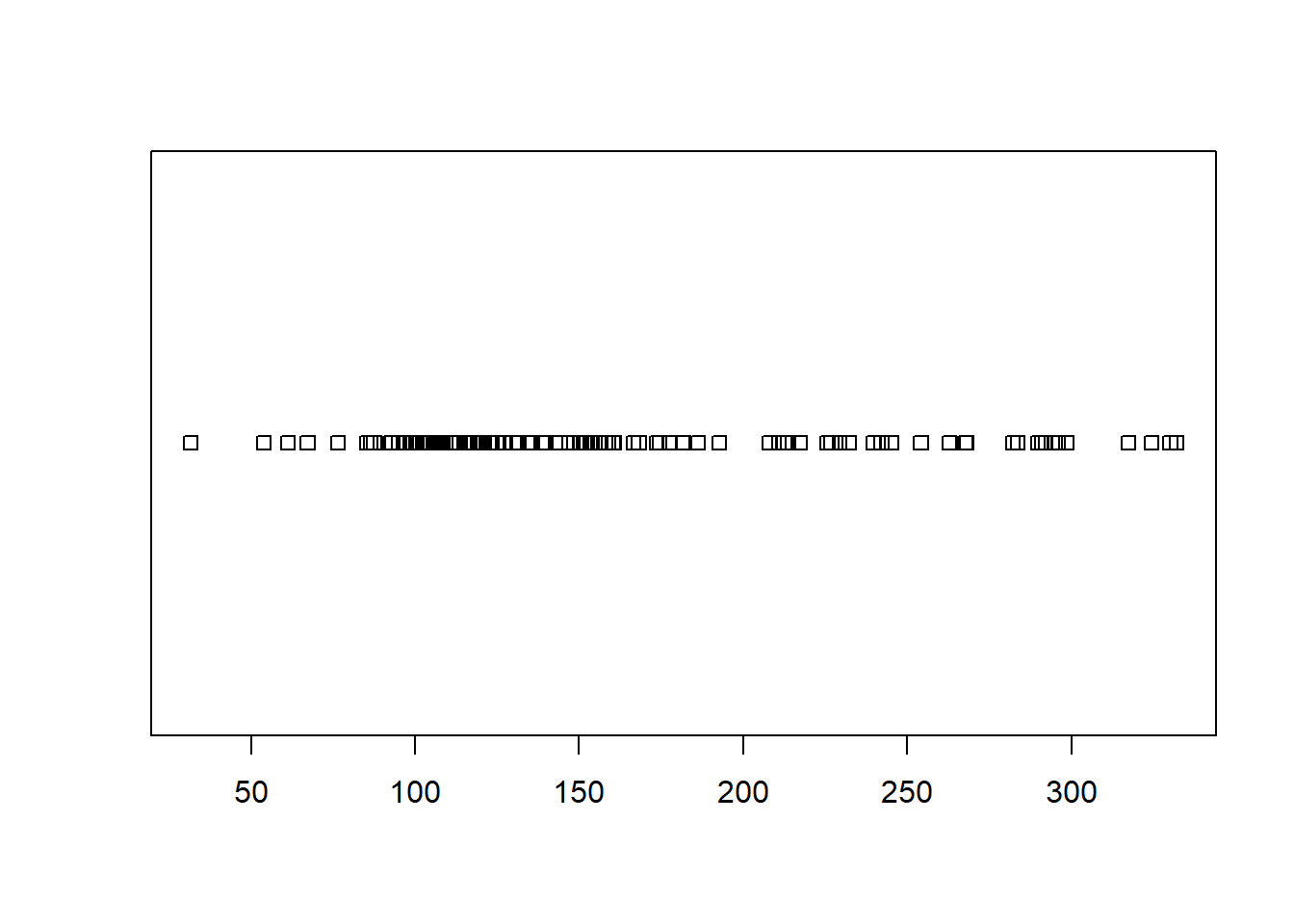
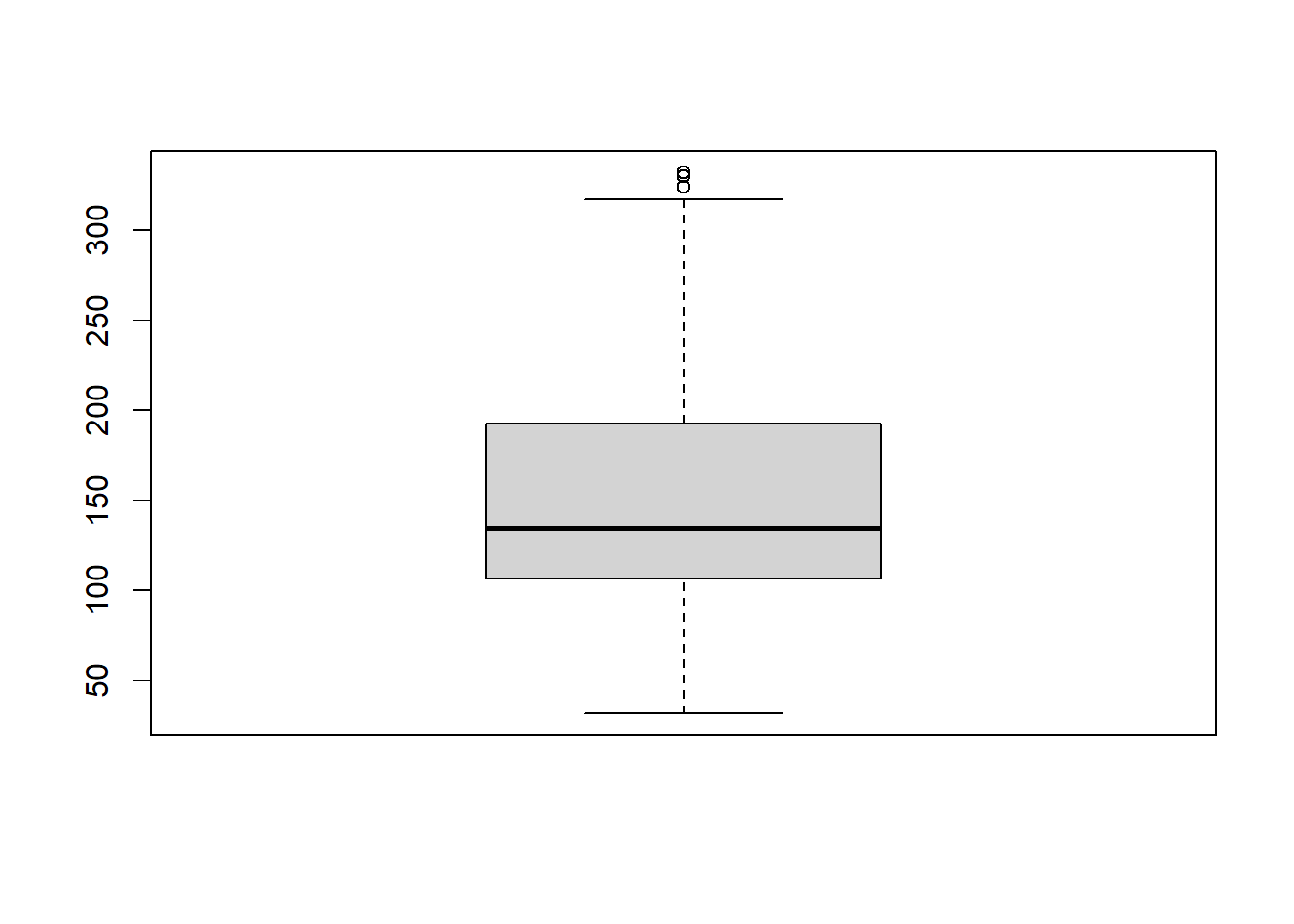
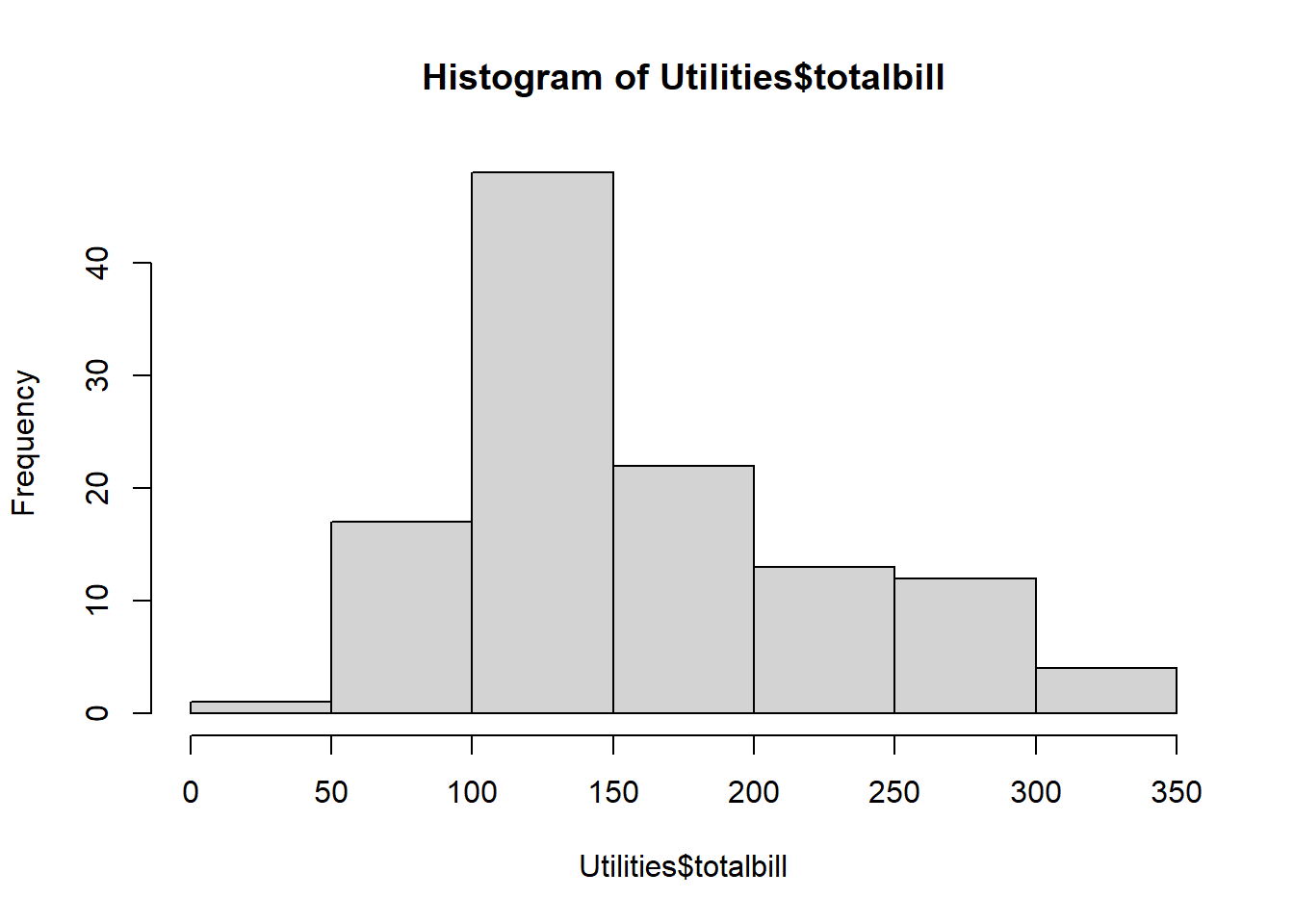
If you run these codes, you should decide to either use the boxplot or the histogram because of the large sample size. The dot plot (stripchart) is simply not useful in this case because it is too messy. However, in either the boxplot or histogram, you should note a right skewed distribution. When data is skewed, the median is the best measure of “typical” values. Thus, the answer to this question would be median. See “Median” in your Numerical Summaries page of your Math 325 Notebook for further details.
Question 2
Use the Orange dataset in RStudio to compute the average circumference of orange trees that are 1,004 days old.
## 118 484 664 1004 1231 1372 1582
## 31.0 57.8 93.2 134.2 145.6 173.4 175.8Question 3
Use the Orange dataset in RStudio to create an appropriate graphic that shows the growth in circumference of orange trees as they age. For which of the following ages of a tree would a circumference of 100mm be most unlikely to occur?
A good choice of graphic when there are two quantitative variables like “circumference” and “age” is a scatterplot. Placing “circumference” as the y-variable and “age” as the x-variable would allow us to clearly see the growth in “circumference” as the trees “age”.
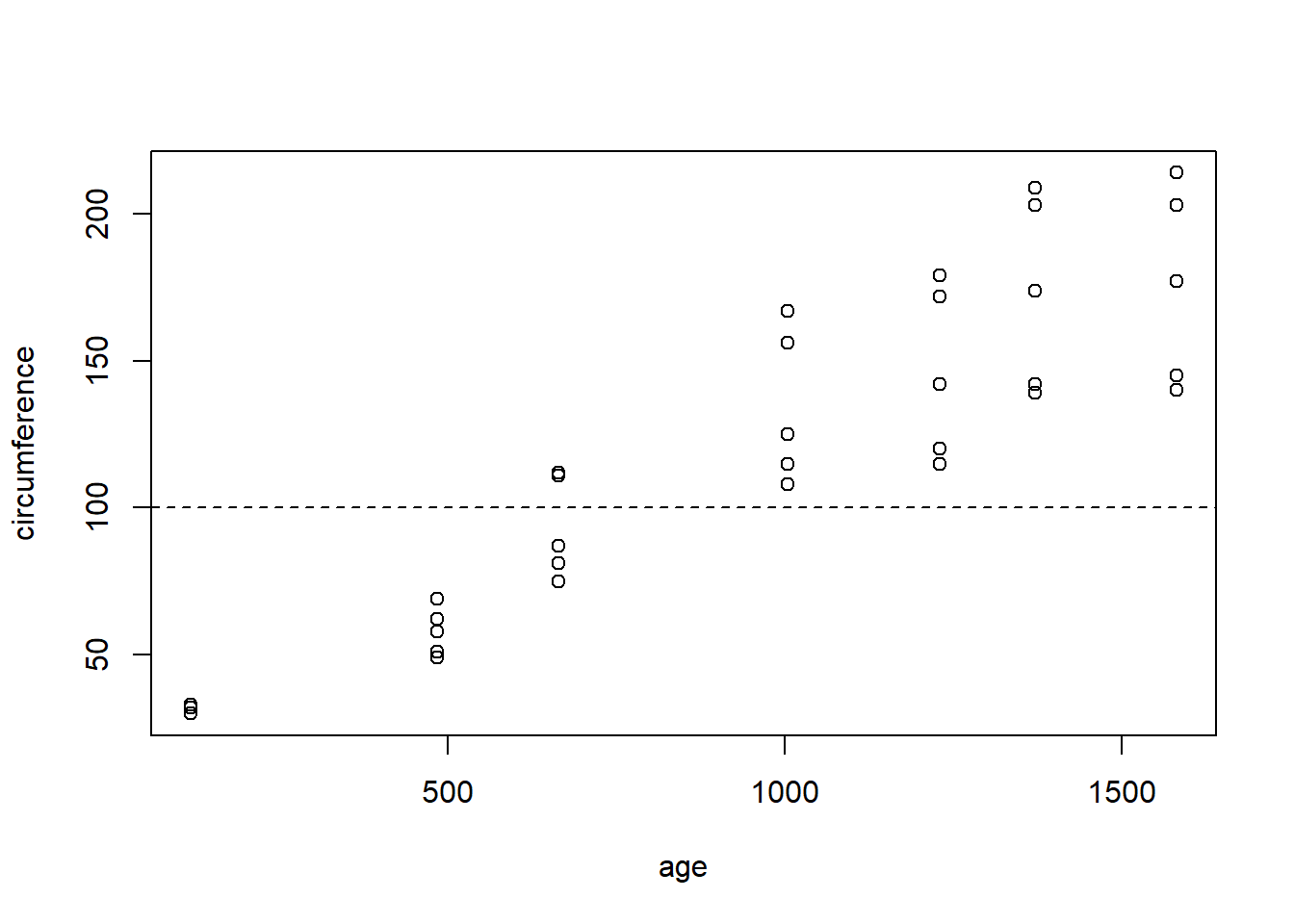
The addition of the horizontal line at a y-value of 100 using “abline(…)” is a bonus piece of code that makes for easy reference on the graphic.
From the ages given in the possible answers, 484 days is the one that is least likely to have a circumference of 100mm because the dots for that age (the ones on the far left of the graph) are incredibly far away from 100mm.
Intro to Data Wrangling & Visualization
Question 1
Use the mtcars dataset in R to compute the mean “Gross horsepower” of both automatic and manual transmission 1974 Motor Trend vehicles.
Run this code to get the answer:
| am | mean(hp) |
|---|---|
| 0 | 160.3 |
| 1 | 126.8 |
Question 2
Use the mtcars dataset in R to make a graph that allows you to see how the quarter mile time (qsec) of 1974 Motor Trend vehicles is effected by the number of carburetors (carb) in the vehicle.
Select the statement below that correctly describes this relationship. — On average, the more carburetors a vehicle has, the faster its quarter mile time.
Since both qsec and carb are quantitative, a scatterplot is the best graphic.
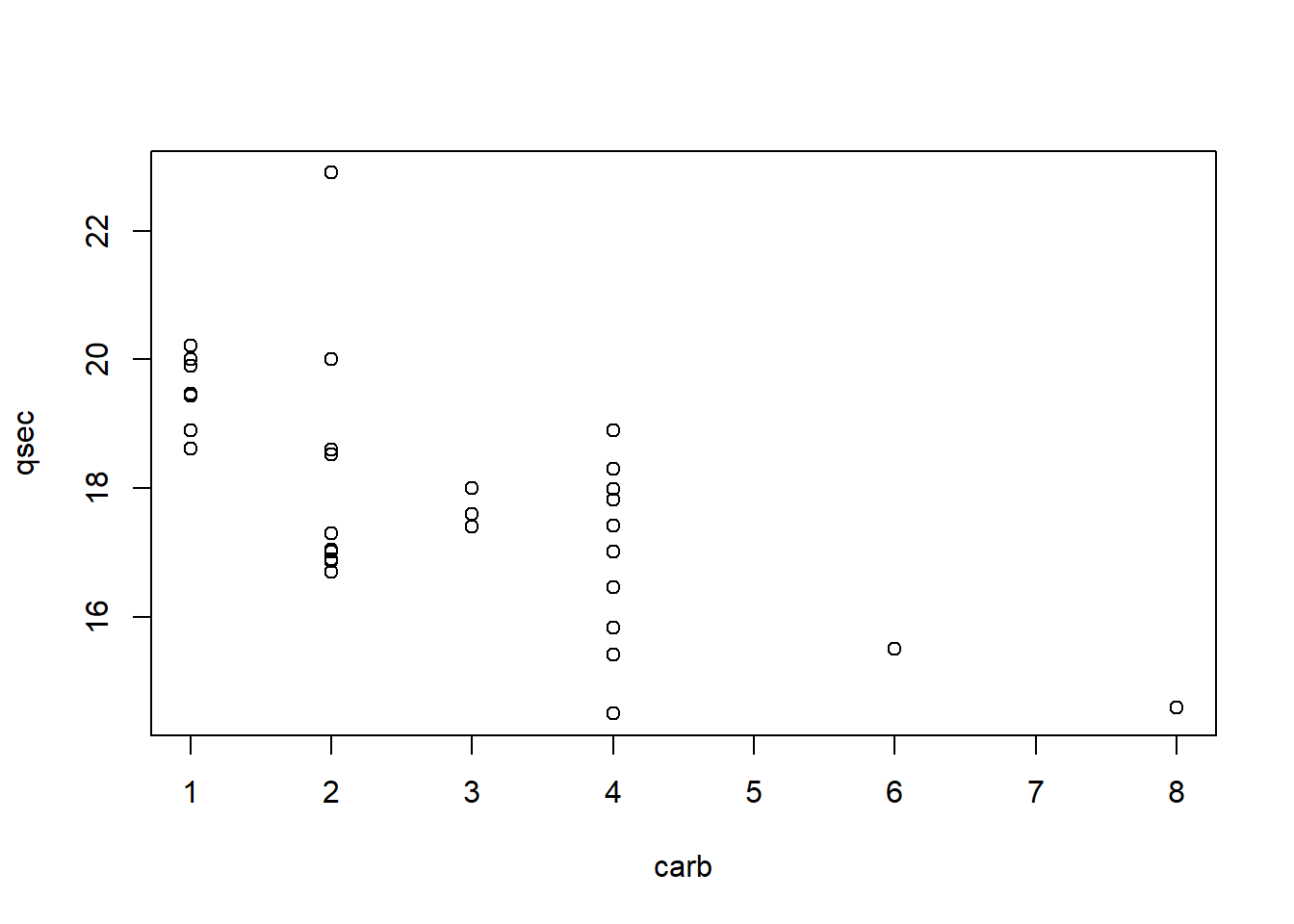
This helps show that the average qsec time (remember, average is the middle of the dots) drops (or gets faster) as the number of carburetors increases.
Question 3
Run the following codes in R. Then select the statement that most appropriately interprets the resulting graph.
palette(c("skyblue","firebrick"))
plot(mpg ~ qsec, data=mtcars, col=as.factor(am), pch=16, xlab="Quarter Mile Time (seconds)", ylab="Miles per Gallon", main="1974 Motor Trend Vehicles")
legend("topright", pch=16, legend=c("automatic","manual"), title="Transmission", bty='n', col=palette())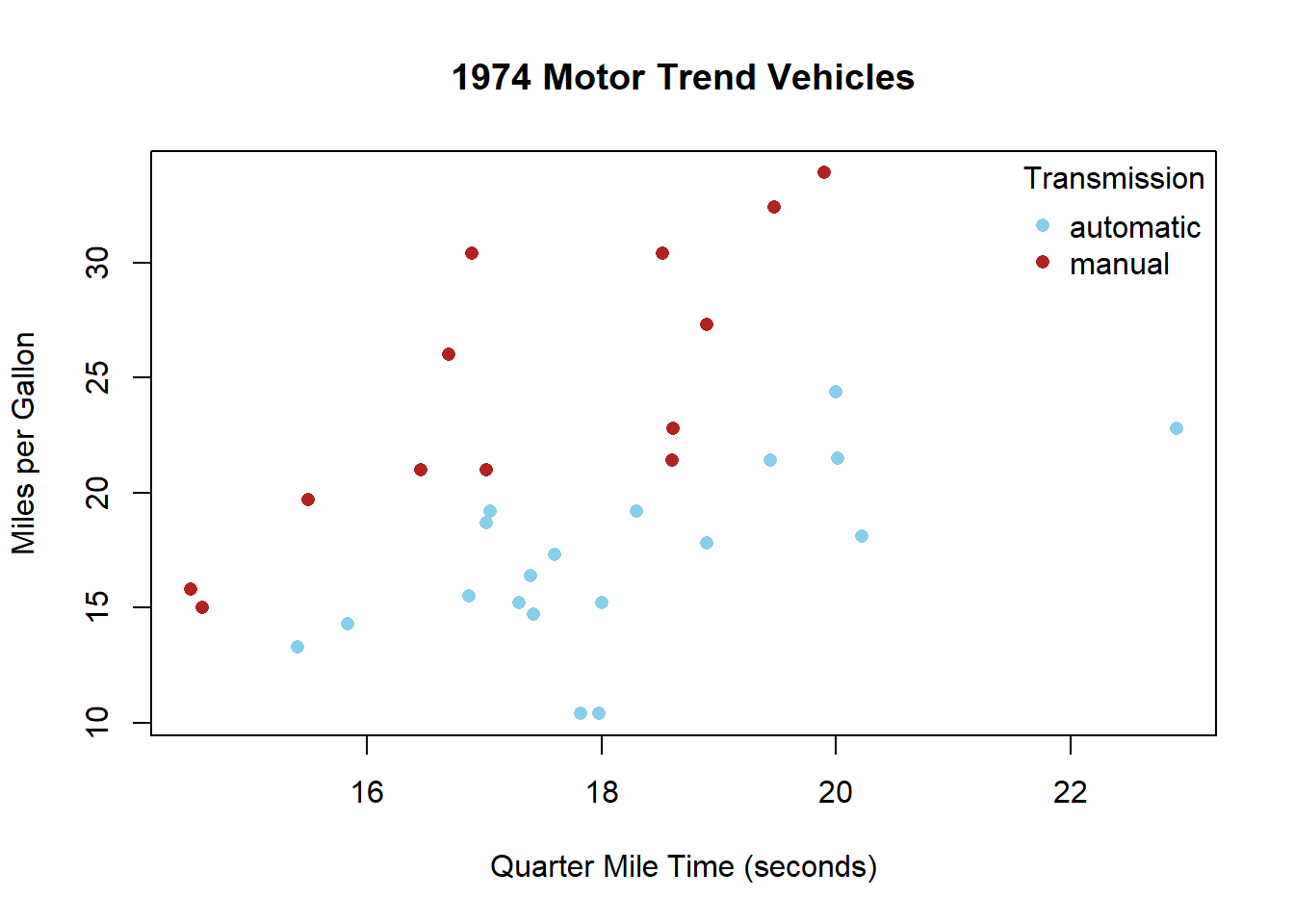
The graph shows that both vehicles with automatic and manual transmissions get better gas mileage the faster their quarter mile time.
The graph produced by the code given shows gas mileage on the y-axis and quarter mile times on the x-axis. Also, as indicated by the legend, the color of the points is determined by whether the vehicle is automatic or manual transmission.
Since both transmission types show positive moderate correlations, we can conclude that higher quarter mile times (which means slower vehicles) correlate with higher gas mileages.
Weeks 3 & 4: t-Tests & Wilcoxon Tests
Overview
You should be able to:
- Classify a scenario as an Independent or Paired Test.
- Classify a scenario as a t Test or Wilcoxon Test.
- Identify a t Test as a parametric test (t distribution) and the Wilcoxon Test as nonparametric.
- State the hypotheses for a t Test or Wilcoxon Test.
- Correctly use
t.test()orwilcoxon.test()in R. - Check requirements.
- Interpret the results.
T-Test
Question 1
Ensure you have library(mosaic) loaded in RStudio and can View(Births78). This dataset records data for every day of the year. In other words, each row of this dataset repesents a day of the year.
In a typical year, there are 52 weeks. However, 52 x 7 = 364, and as most of us know, there are 365 days in a year. This means that every year, at least one day gets to happen more than 52 times.
Use appropriate R commands and the Births78 dataset to determine which day of the week in 1978 occurred 53 times.
| wday | n() |
|---|---|
| Sun | 53 |
| Mon | 52 |
| Tue | 52 |
| Wed | 52 |
| Thu | 52 |
| Fri | 52 |
| Sat | 52 |
Question 2
Let μ represent the average number of births that a occur on a given day of the week, like Wendesday or Thursday.
Use the Births78 dataset in RStudio to test the following hypotheses.
\[ H_0: \mu_\text{Wednesday} - \mu_\text{Thursday} = 0 \]
\[ H_a: \mu_\text{Wednesday} - \mu_\text{Thursday} \neq 0 \]
Select the p-value of the test from the options below.
BirthsWedThu <- dplyr::filter(Births78, wday %in% c("Wed","Thu"))
t.test(births ~ wday, data=BirthsWedThu, mu=0, alternative="two.sided", conf.level=0.95)##
## Welch Two Sample t-test
##
## data: births by wday
## t = 0.14432, df = 98.945, p-value = 0.8855
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -183.3878 212.1571
## sample estimates:
## mean in group Wed mean in group Thu
## 9498.019 9483.635Question 3
What two things are required to compute a p-value?
A test statistic and a sampling distribution of the test statistic.
Wilcoxon Test
Question 1
This question needs library(car).
Use the Salaries dataset in R to find the number of male and female assistant professors in the dataset.
Run the following code to get the answer:
| rank | sex | n() |
|---|---|---|
| AsstProf | Female | 11 |
| AsstProf | Male | 56 |
| AssocProf | Female | 10 |
| AssocProf | Male | 54 |
| Prof | Female | 18 |
| Prof | Male | 248 |
Question 2
Create an appropriate graphic using the Salaries dataset in R that would allow you to compare the distribution of salaries for faculty in discipline A (“theoretical”) and discipline B (“applied”) departments.
Run the following code to get the answer:
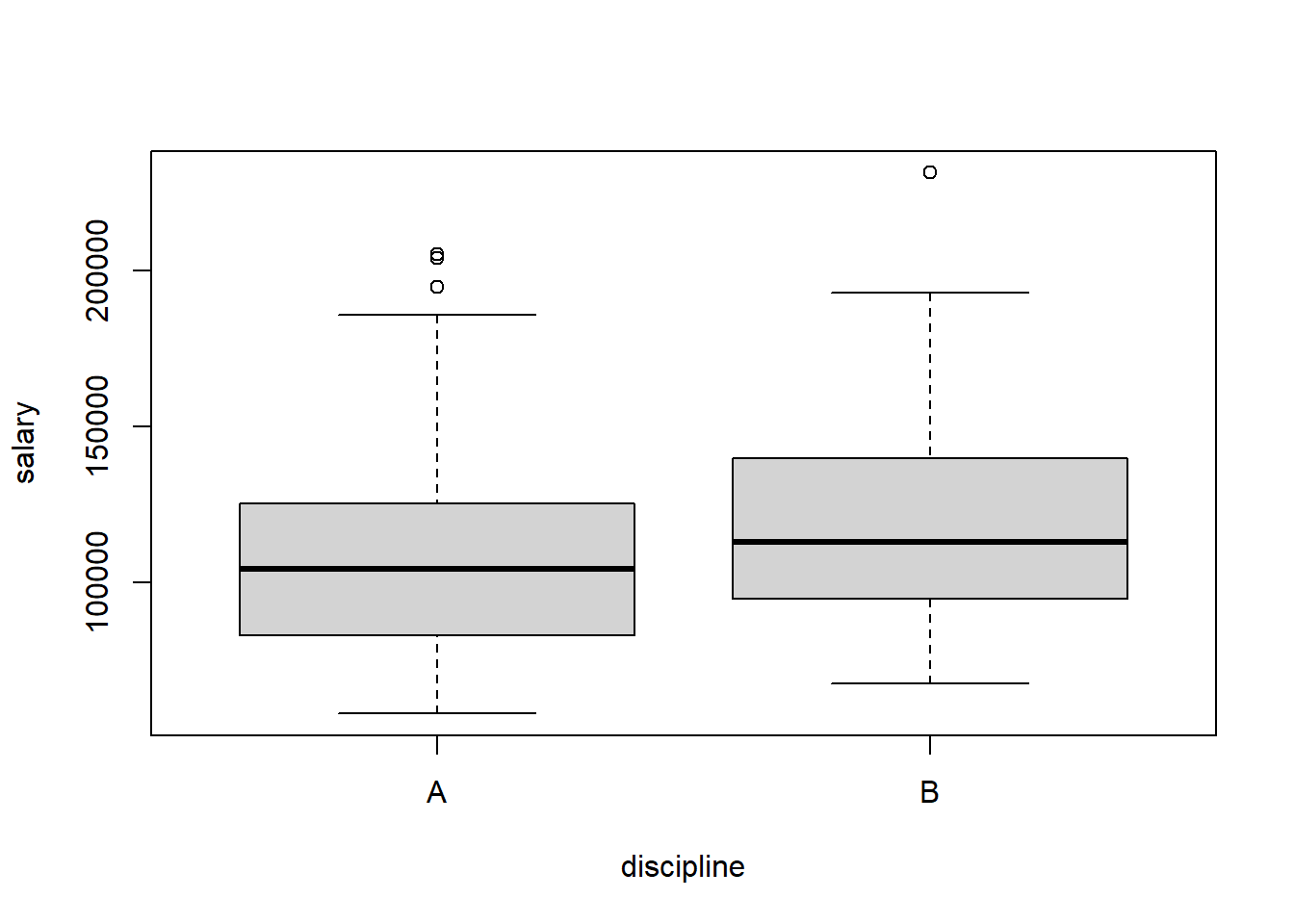
Or, to be more complete:
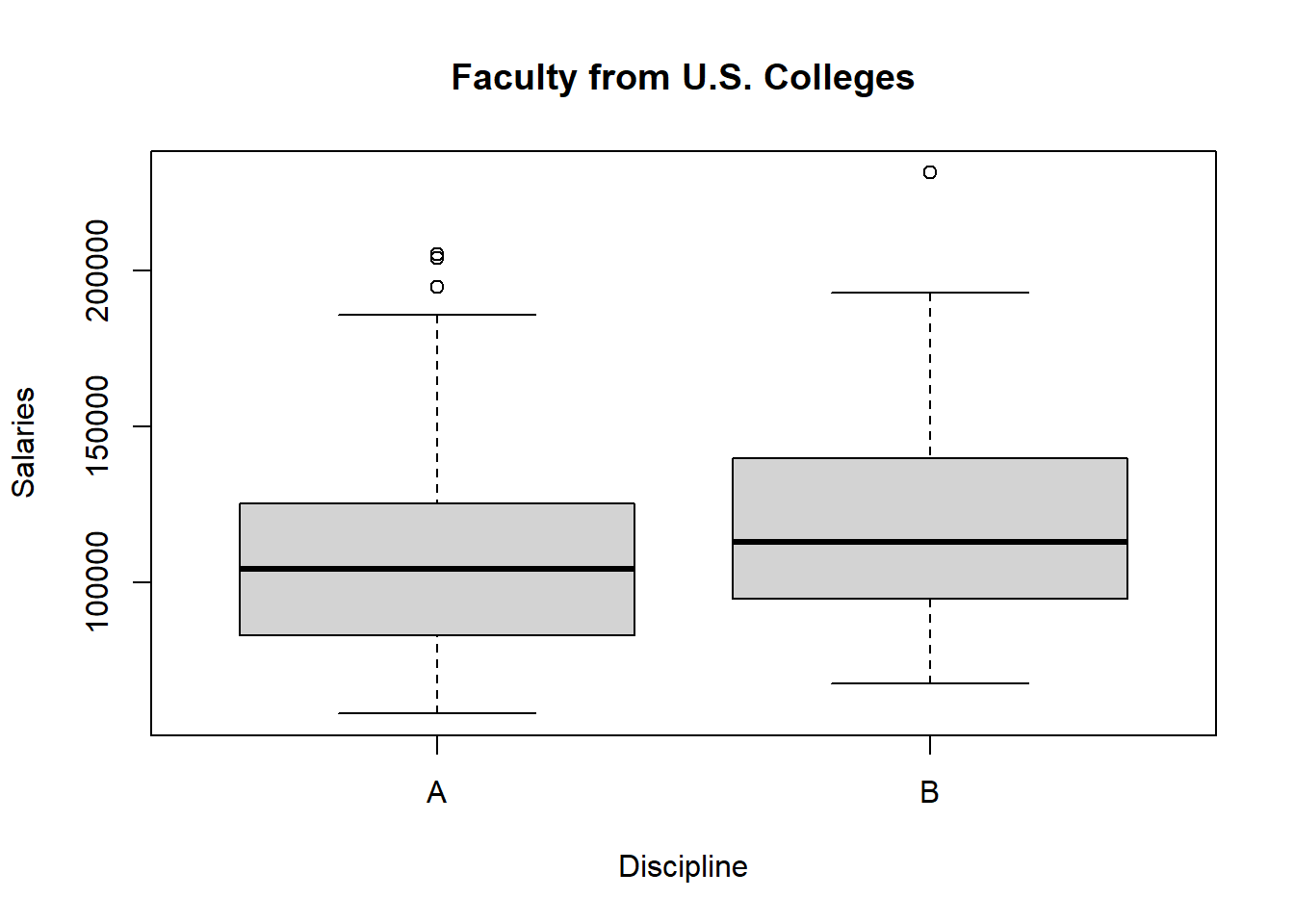
Question 3
Perform an appropriate Wilcoxon Test of the following hypotheses using the Salaries dataset in R.
H0:median discipline A salaries−median discipline B salaries=0 Ha:median difference of salaries≠0
Select the response below showing the correct test statistic, p-value, and conclusion of the test based on a significance level of 0.05.
| Test statistic | P value | Alternative hypothesis |
|---|---|---|
| 15710 | 0.0007516 * * * | two.sided |
Weeks 5 & 6: ANOVA & Kruskal-Wallis
Overview
You should be able to:
- Classify a scenario as an ANOVA or Kruskal-Wallis Test.
- Recognize that the Kruskal-Wallis test is a nonparametric test.
- Identify an ANOVA as a parametric test (F distribution) and the Kruskal-Wallis Test as nonparametric.
- Know the difference between “Within Groups” and “Between Groups” variances for ANOVA.
- State the hypotheses for an ANOVA or Kruskal-Wallis Test.
- Correctly use
aov(),summary(),plot(..., which=1:2), andkruskal.test()in R. - Check requirements (constant variance and normal errors for ANOVA; not too many ties present for Kruskal-Wallis).
- Interpret the results.
ANOVA Test
Question 1
In a certain student’s ANOVA analysis the “Between groups variance” was 18.52 while the “Within groups variance” was 4.9. What was the value of the test statistic of their ANOVA test?
As shown in the Explanation tab of the ANOVA page of the Math 325 Notebook, the ANOVA test statistic is an F statistic. It is calculated by taking the “Between groups variance” and dividing this by the “Within groups variance”. Thus 18.52/4.9 = 3.779592 which rounds to 3.78.
Question 2
These were made using the length, domhand, and sex columns of the KidsFeet dataset.
Perform an ANOVA that would test the signfiicance of the patterns of the means that are shown in these three graphs. Based on your p-values and these graphs, which of the following is a correct conclusion to reach?
Among fourth graders, right handed boys have longer feet on average than left handed boys while the opposite is true for girls.
Question 3
n the KidsFeet dataset, what is the average length of feet for fourth grade boys that are left handed? — 24.1 cm
Kruskal-Wallis Test
Question 1
Use the Salaries dataset in R, library(car), to test the hypotheses
\[ H_0: \text{The distribution of salary is the same for Associate, Assistant, and Full Professors.} \]
\[ H_a: \text{The distribution of salary differs for at least one type of Professor.} \]
Report the test statistic and conclusion of your test.
Test is performed with:
##
## Kruskal-Wallis rank sum test
##
## data: salary by rank
## Kruskal-Wallis chi-squared = 194.01, df = 2, p-value < 2.2e-16Conclusions are obtained from:
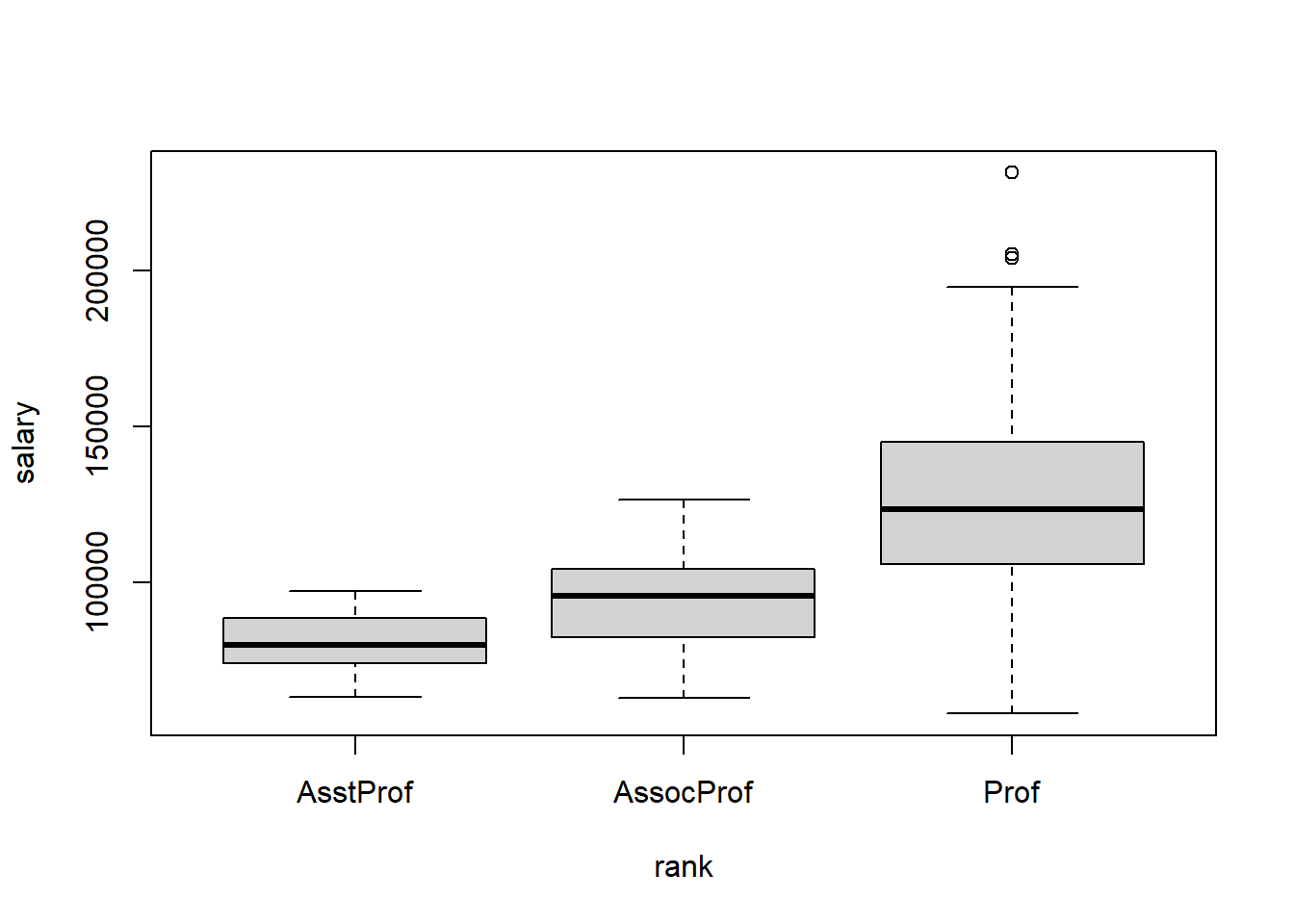
which shows Full Professors have the highest distribution, Associate Professors the next highest, and Assistant Professors have the lowest distribution.
Question 2
A waiter at a local restaurant collects data on how much they earn in tips (per person) when groups of people each pay separately for their meal versus when one member of the group pays for everyone. Their very small sample of data is as follows.
| Group ID | Number of People in Group | Type of Payment | Total Tip Amount |
|---|---|---|---|
| 1 | 5 | Each Paid | $16 |
| 2 | 3 | One Paid for All | $10 |
| 3 | 4 | One Paid for All | $9 |
| 4 | 4 | Each Paid | $15 |
| 5 | 6 | Each Paid | $21 |
| Per Person Amount |
|---|
| $3.20 |
| $3.33 |
| $2.25 |
| $3.75 |
| $3.50 |
Which hypothesis test would be most appropriate for deciding if the average per person tip amount is higher when people that eat in groups each pay individually for their meal?
While techincally you could use a Kruskal-Wallis Test, when there are only two groups in the data, it is equivalent to performing a Wilcoxon Rank Sum Test. So the best decision would be to use the Wilcoxon Rank Sum Test. An Independent Samples t Test might also be useful if the data can be assumed to be normal. However, given the small sample size and the fact that there are no repeated values, the Wilcoxon Test is the safer option.
Question 3
Which of the following correctly describes the test statistic, H, of the Kruskal-Wallis Test?
See “Step 5” of the Explanation file of the Kruskal-Wallis Test for details about the Kruskal-Wallis H Statistic.
ANOVA uses the F = (Between groups variance)/(Within groups variance) test statistic.
The One Sample t Test measures how far the sample mean is from mu for its test statistic.
The Wilcoxon Rank Sum test sums the ranks from one of the groups for its test statistic.
Weeks 7 - 11: Regression
Overview
Linear
You should be able to:
- Identify a scenario as a linear regression.
- Recognize the explanatory and response variables of the regression.
- State both the t Test hypotheses and F Test hypotheses and recognize when to use either.
- Correctly use
lm(),summary(), andplot(..., which=1:2)in R. - Check requirements (linearity, constant variance, normal errors, fixed x-values, and independent errors).
- Interpret the slope(s) and intercept of the regression.
- Make predictions using the regression model.
Logistic
You should be able to:
- Identify a scenario as a logistic regression.
- Recognize the explanatory variables and binomial response variable of the regression.
- State the Z Test hypotheses for any single coefficient in the regression.
- Correctly use
glm(),summary(), andcurve()in R. - Check the goodness-of-fit of the logistic regression using an appropriate goodness-of-fit test (deviance residuals vs Hosmer-Lemeshow tests).
- Interpret the effect of a slope term on the odds ratio.
- Explain the difference between an odds and a probability.
- Make predictions of probabilities using the logistic model.
Simple Linear Regression
Question 1
Use the KidsFeet dataset from library(mosaic) to perform a regression of the length of a child’s foot (Y) on the width of a child’s foot (X).
What is the estimated slope and intercept of the least squares regression line for this data?
##
## Call:
## lm(formula = length ~ width, data = KidsFeet)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.6331 -1.0372 0.2299 0.7128 1.9642
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.8172 2.9381 3.341 0.00192 **
## width 1.6576 0.3262 5.081 1.1e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.025 on 37 degrees of freedom
## Multiple R-squared: 0.411, Adjusted R-squared: 0.3951
## F-statistic: 25.82 on 1 and 37 DF, p-value: 1.097e-05Question 2
Continue using the KidsFeet regression that you performed in the last problem. In other words, the regression of the length of a child’s foot (Y) on the width of the child’s foot (X).
Plot the regression in R. Then select the plot below that correctly depicts the scatterplot and regression line of this regression.
Run this code to get the answer:
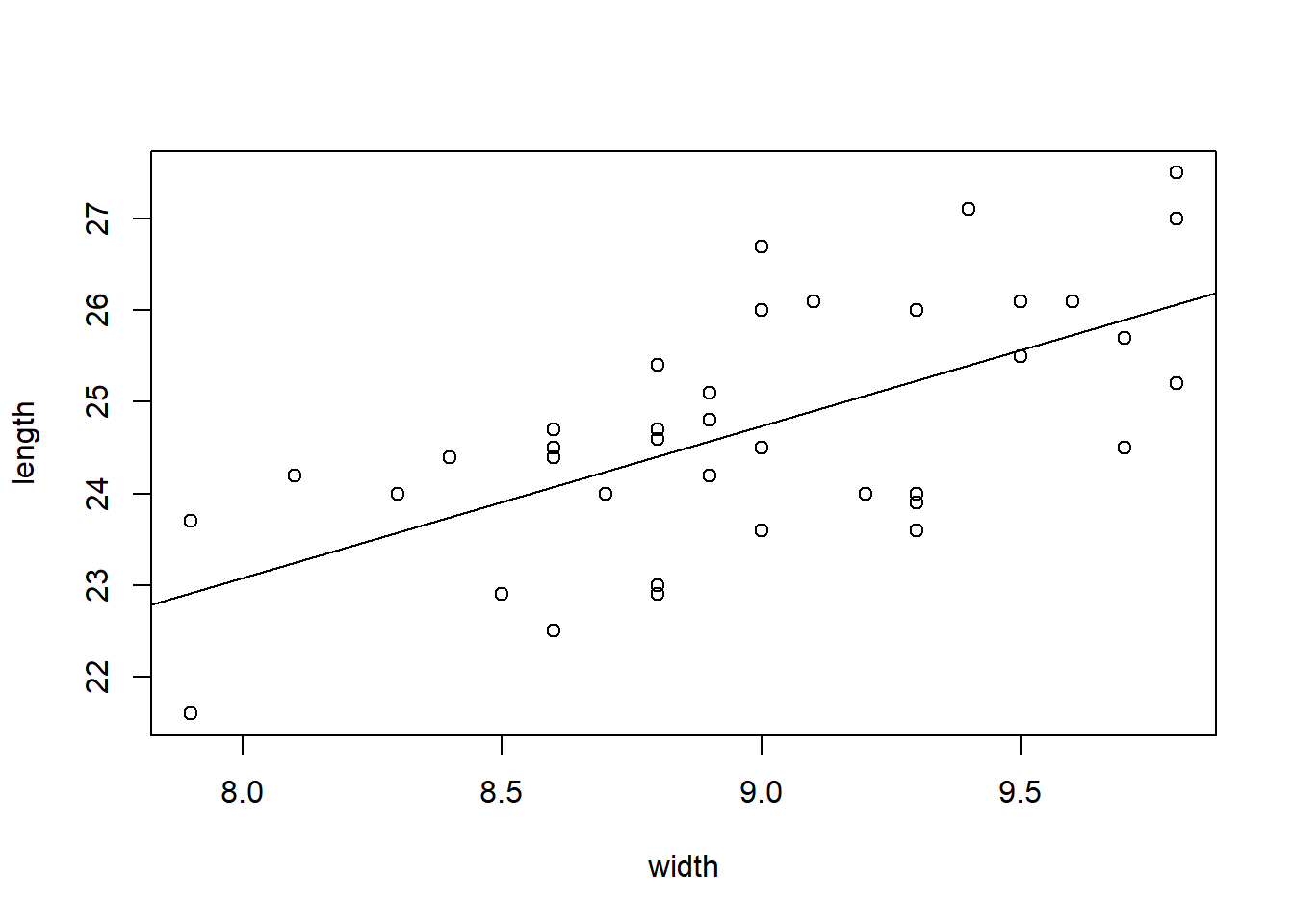
Question 3
The residual plot from the regression of the length of a child’s foot on the width of the child’s foot (using the KidsFeet dataset from library(mosaic)) shows the following residual plots.
Select the statement that most correctly interprets these plots.
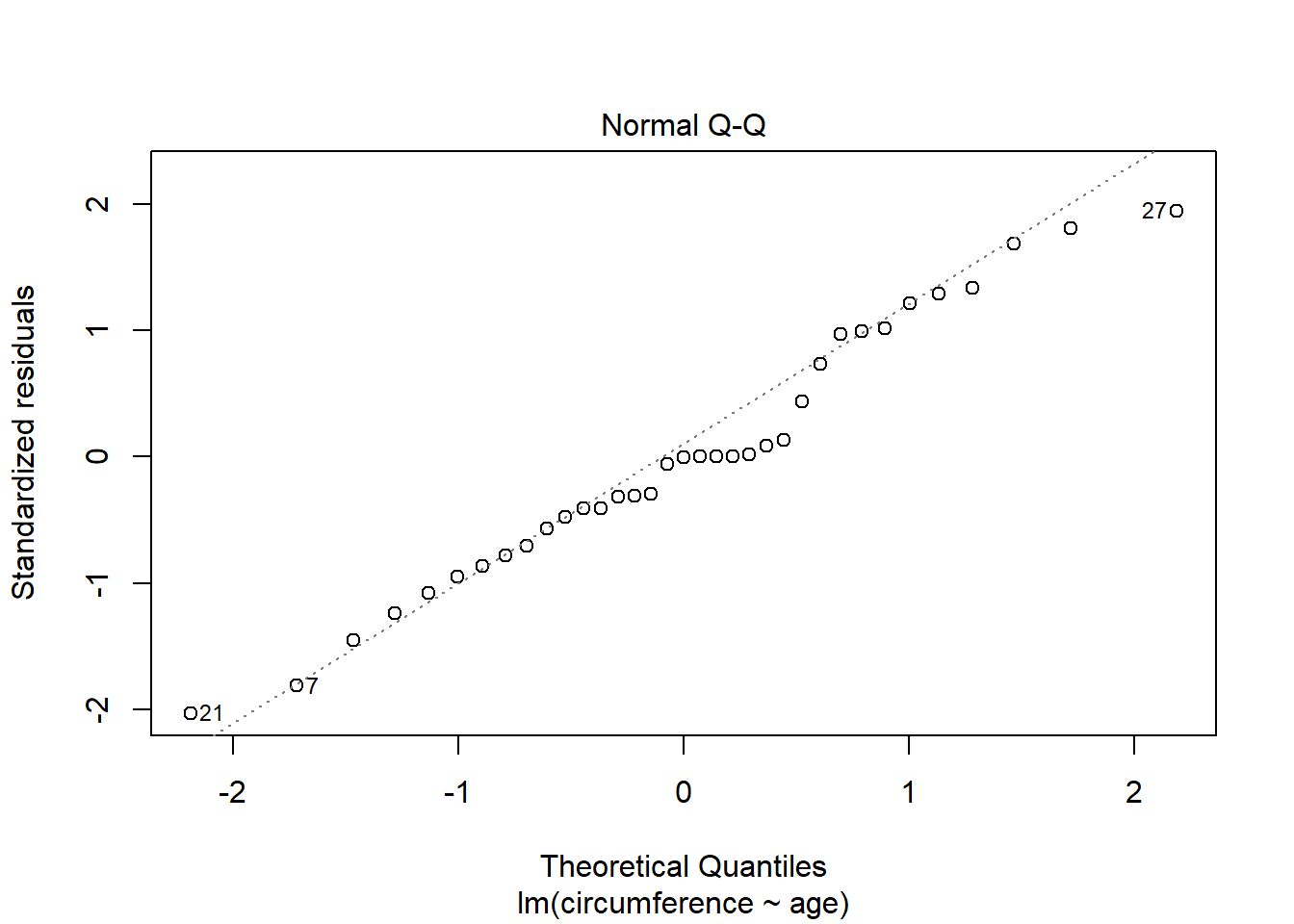
The “Residuals vs Fitted” plot shows the data to be linear and to have constant variance. However, the “Normal Q-Q” plot shows some evidence of non-normality of the residuals.
See the “Explanation” tab for Linear Regression under the section “Checking the Assumptions”.
Click on the links for “Explanation” of both the “Residuals versus Fitted-values Plot” and the “Q-Q Plot of the Residuals”.
Multiple Linear Regression
Question 1
Use the Orange dataset in R to perform a linear regression of the circumference (y) of an orange tree according to the age of the tree (x).
Which regression assumption is not satisfied for this regression?
Run the following code to get the answer:
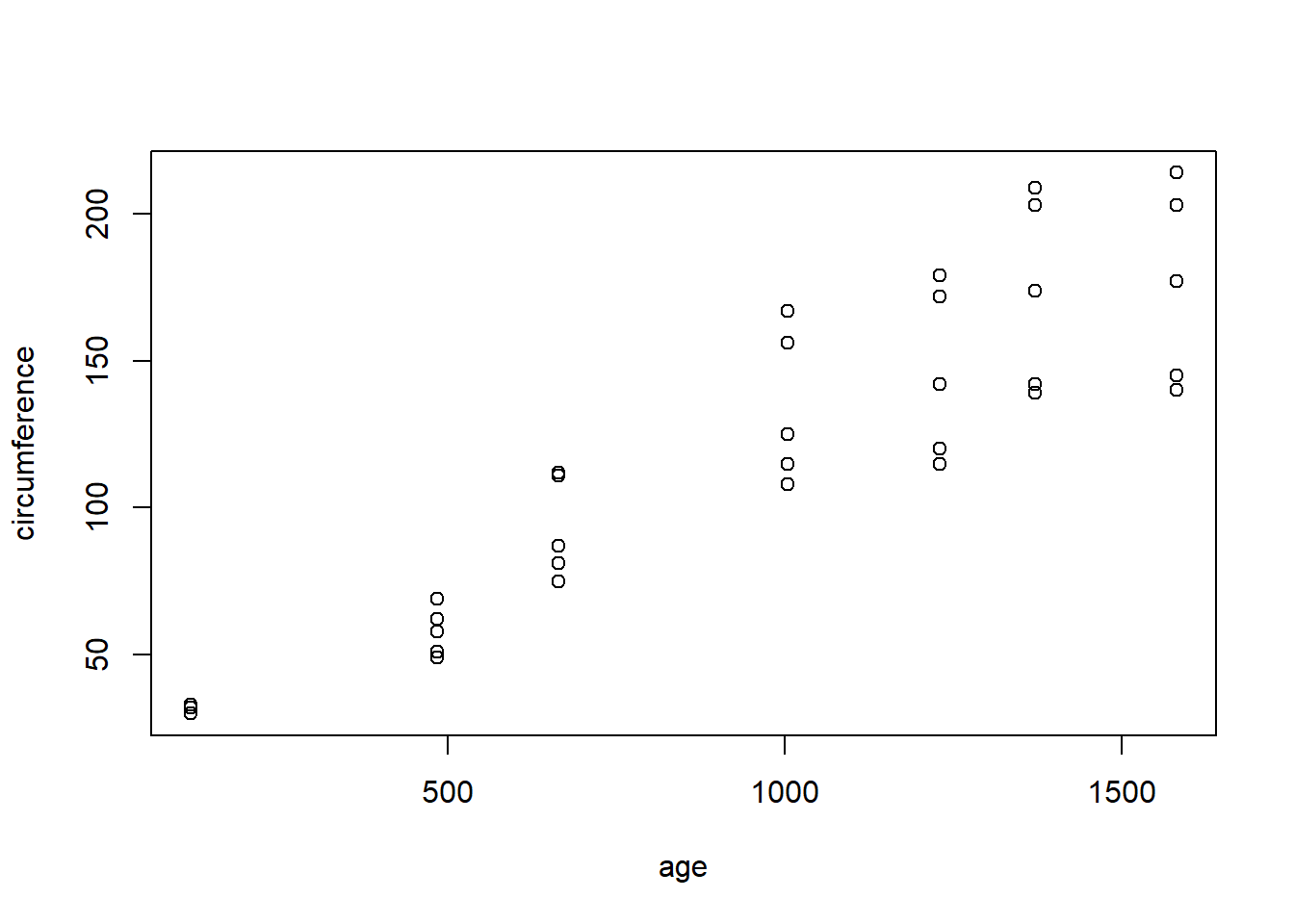
orange.lm <- lm(circumference ~ age, data=Orange)
plot(orange.lm, which=1) #looks very linear, but variance is increasing (so not constant)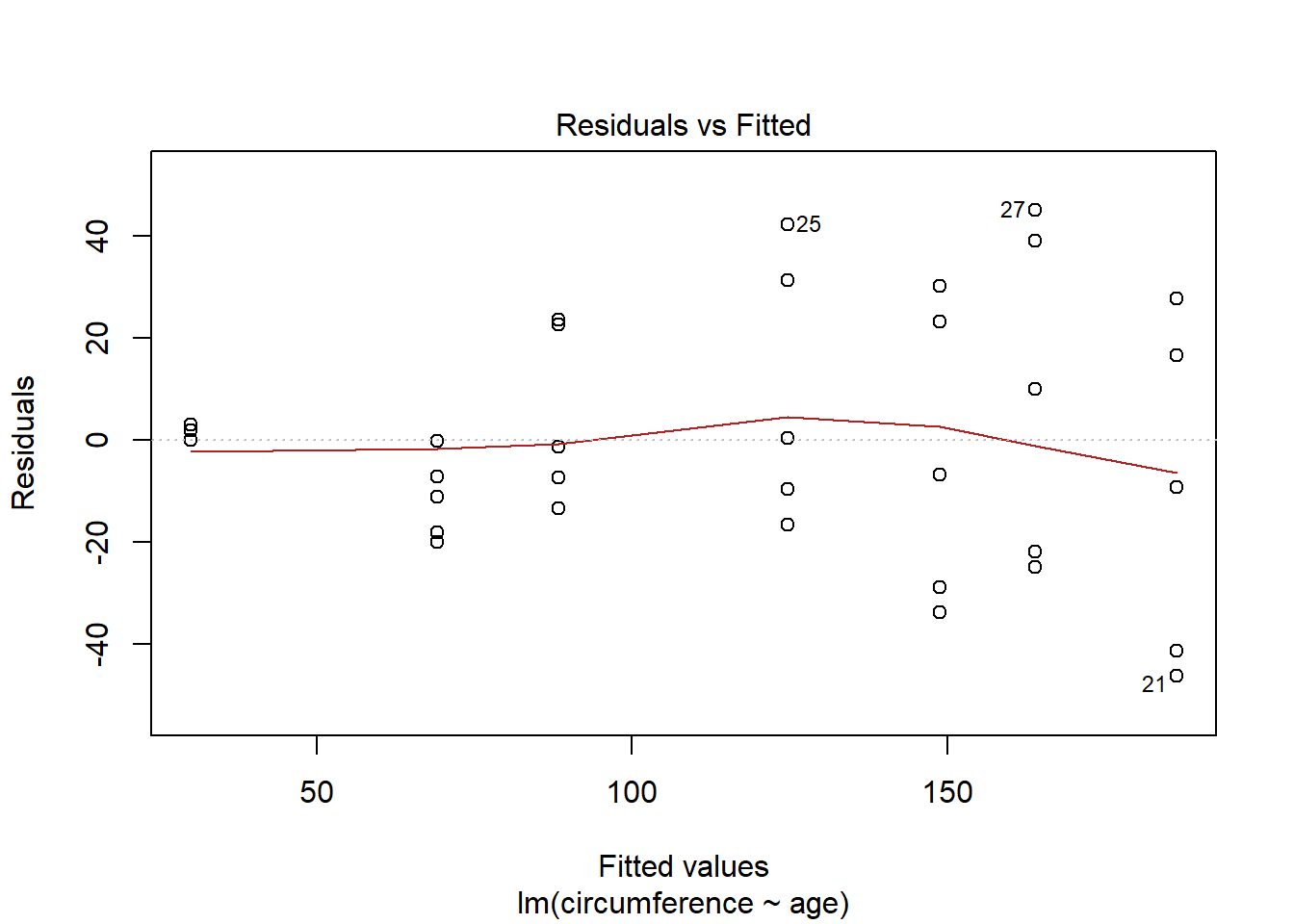
Question 2
The following regression was performed in R. The lm( ) output from the regression is shown below.
What is the y-intercept and slope of the line for Tree #2 shown in the plot below?
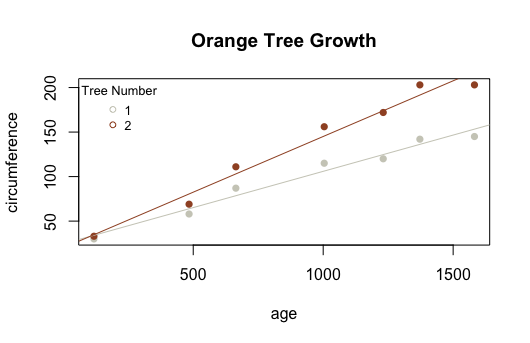
Y-intercept = 19.9609 Slope = 0.1250618
Question 3
Suppose the regression model
\[ Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i \] is used to model the KidsFeet dataset in R using this code, which you should run in R:
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 11.13 | 3.143 | 3.541 | 0.001123 |
| width | 1.558 | 0.3364 | 4.631 | 4.616e-05 |
| as.factor(birthyear)88 | -0.504 | 0.4409 | -1.143 | 0.2606 |
| Observations | Residual Std. Error | \(R^2\) | Adjusted \(R^2\) |
|---|---|---|---|
| 39 | 1.021 | 0.4316 | 0.4001 |
Note that a plot of this regression is shown for your reference.
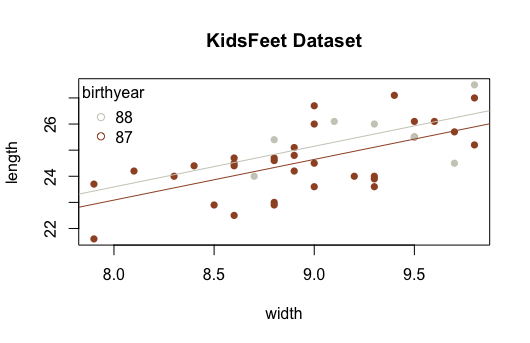
Which of the following correctly interprets the results of this regression?
Because the p-value for the β2 term is not significant, the two lines should really just be one line.
Simple Logistic Regression
Question 1
Run the following codes in R.
library(mosaic)
View(Gestation)
?Gestation
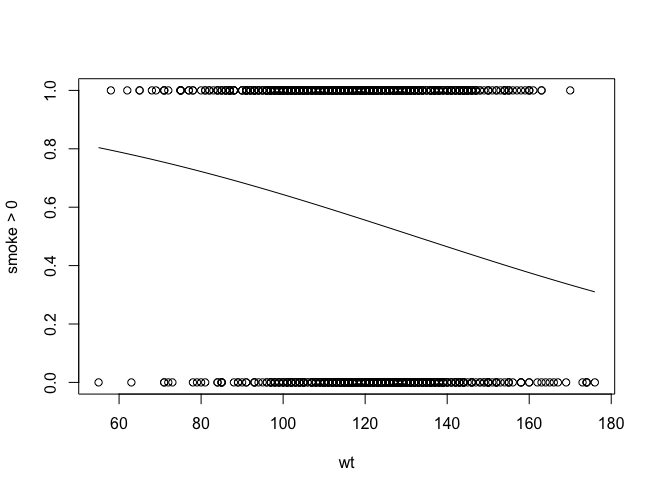
Use an appropriate test to determine if the birth weight in ounces of a baby (wt) can be used to predict the probability that the mother smoked at all (smoke>0) during or prior to the pregnancy. The graphic of the correct analysis is shown below.
What are the values of b0 and b1 for the curve shown in the graphic below?
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | 26.57 | 67575 | 0.0003931 | 0.9997 |
| wt | 8.432e-11 | 559 | 1.509e-13 | 1 |
(Dispersion parameter for binomial family taken to be 1 )
| Null deviance: | 0.000e+00 on 1225 degrees of freedom |
| Residual deviance: | 7.113e-09 on 1224 degrees of freedom |
Question 2
Here is the output of a logistic regression performed in R.
Coefficients: Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.6035 2.3514 -2.808 0.00498 mpg 0.3070 0.1148 2.673 0.00751
What is the predicted value for P(Yi=1|xi=25) ?
## [1] 0.7448821Question 3
Consider again the logistic regression output shown below.
Coefficients: Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.6035 2.3514 -2.808 0.00498 mpg 0.3070 0.1148 2.673 0.00751
Which of the following correctly interprets these results?
To intepret the effect of mpg (the x-variable) on the odds, we compute exp(0.3070), which gives the value of eb1 . See the Overview page of Logistic Regression for an explanation.
Coefficients: Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.6035 2.3514 -2.808 0.00498 mpg 0.3070 0.1148 2.673 0.00751
Since exp(0.3070) = 1.359341, we find that the odds of a success, i.e., that Yi =1 increases by 35.9341%, which rounds to 36% for every 1 unit increase in x.
Notices that the 35.9341 came from 1.359341. If you have 1.36 of what you originally had, then you increased by 0.36 or 36%.
## [1] 1.359341Week 12 - 13: Chi Squared Tests of Independence & Permutation Tests
Overview
Chi-Squared Test
You should be able to:
- Identify a scenario as appropriate for a Chi squared Test.
- Explain what an expected count is and how it is calculated.
- State the hypotheses.
- Correctly use
chisq.test(),test.object$residuals, andbarplot()in R. - Check the requirements using the expected counts.
- Interpret the results using Pearson Residuals when the p-value is significant.
Randomization Testing
You should be able to:
- State the logic behind the permutation test used to perform the Nonparametric Chi-squared Test.
- Perform a permutation test in R for any of the scenarios including: Independent Samples, Paired Samples, Regression, or Chi-squared.
- Recognize that the only difference between a permutation test and the other tests taught in this course is in how the p-value is calculated. Everything else is the same.
Chi Squared Tests of Independence
Question 1
What type of statistical test would be appropriate for understanding how gender impacts the risk a person of a certain age has of having a heart attack?
We are trying to predict an outcome, whether or not the person will experience a heart attack, using their age and gender. Age is a quantitative measurement, gender is a qualitative measurement, and the response variable Y could be 1 for a heart attack and 0 for no heart attack. This is the perfect scenario of a multiple logistic regression.
Question 2
Which statistical method would be best suited for determining how the age and gender of an individual can predict their annual income, measured in thousands of dollars?
The response variable of this scenario, annual income measured in thousands, is quantitative. Since we have a quantitative explanatory variable of age and a qualitative explanatory variable of gender, a multiple linear regression would be the best choice.
Question 3
Run the following codes in R:
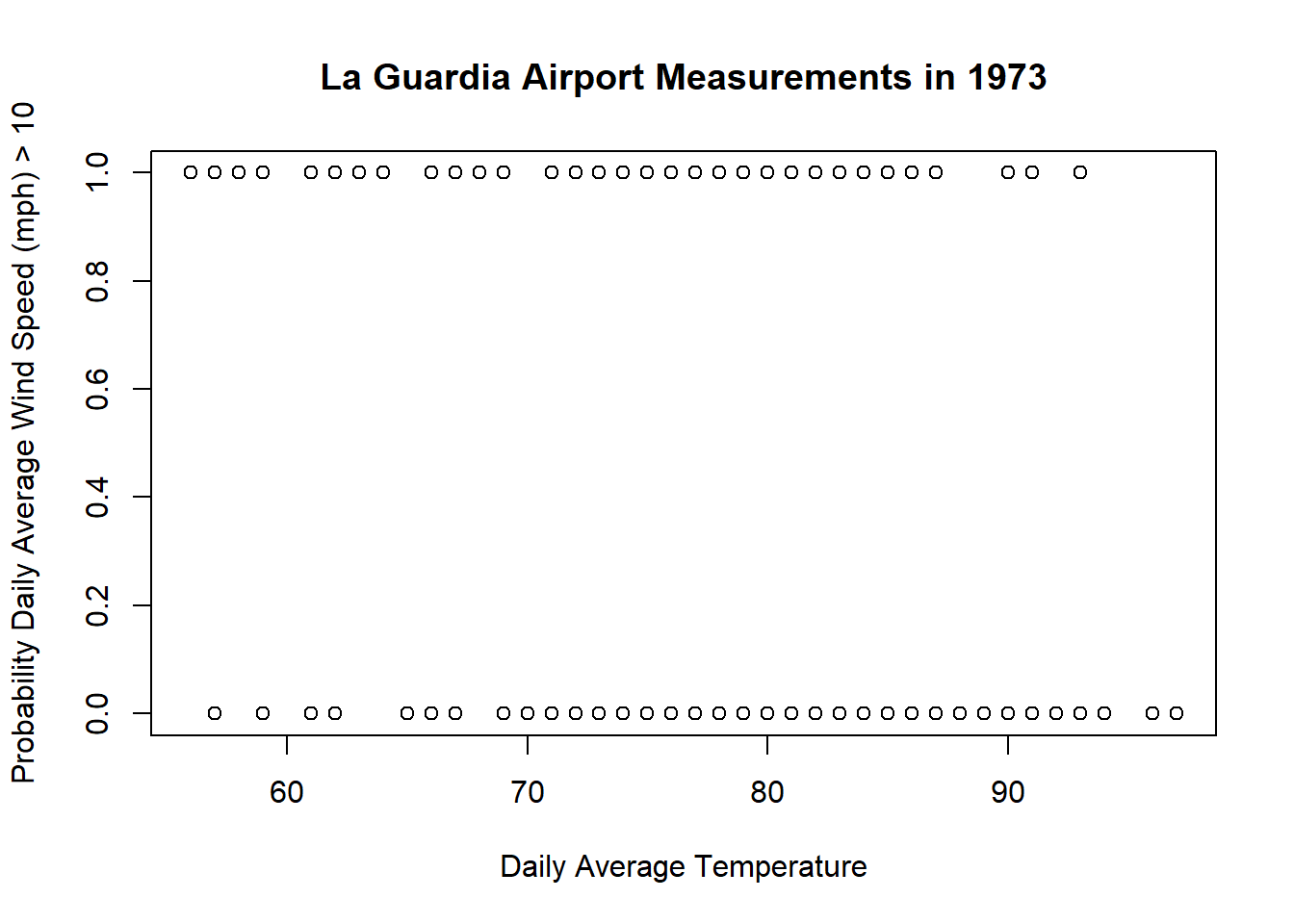
During which month is there a significant change in the probability that the daily average wind speed will be greater than 10 mph, for all values of daily average temperature?
##
## Call:
## glm(formula = Wind > 10 ~ Temp + as.factor(Month), family = binomial,
## data = airquality)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.7457 -0.9825 -0.6264 1.0925 1.8717
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 6.99664 1.92840 3.628 0.000285 ***
## Temp -0.10140 0.02867 -3.537 0.000405 ***
## as.factor(Month)6 0.87217 0.65487 1.332 0.182919
## as.factor(Month)7 0.73891 0.74202 0.996 0.319348
## as.factor(Month)8 1.00550 0.73050 1.376 0.168682
## as.factor(Month)9 1.25238 0.64839 1.932 0.053418 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 211.57 on 152 degrees of freedom
## Residual deviance: 190.09 on 147 degrees of freedom
## AIC: 202.09
##
## Number of Fisher Scoring iterations: 4Random Testing
Question 1
Which statistical test would be the most appropriate for analyzing the following data?
A local restaurant records how many customers purchased a meal during the breakfast hours (7-9 AM), the lunch-time hours (10 AM - 2 PM) and the dinner-time hours (4 PM - 9 PM). They have this information for several months and want to know how the meal traffic (number of customers) differs on weekends vs. weekdays.
The data from this experiment would look similar to the following.
| Customer ID | Time of Day | Day of Week |
|---|---|---|
| 1 | Breakfast | Weekday |
| 2 | Lunch | Weekend |
There are two variables (columns) to this dataset, “Time of Day” and “Day of Week”. Since both are qualitative, the most appropriate test is the chi squared test of independence.