Logistic Regression
Regression for a qualitative binary response variable \((Y_i = 0\) or \(1)\). The explanatory variables can be either quantitative or qualitative.
Use Logistic Regression to predict true - false with numeric values
Simple Logistic Regression Model
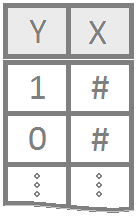
Regression for a qualitative binary response variable \((Y_i = 0\) or \(1)\) using a single (typically quantitative) explanatory variable.
Overview
The probability that \(Y_i = 1\) given the observed value of \(x_i\) is called \(\pi_i\) and is modeled by the equation
The coefficents \(\beta_0\) and \(\beta_1\) are difficult to interpret directly. Typicall \(e^{\beta_0}\) and \(e^{\beta_1}\) are interpreted instead. The value of \(e^{\beta_0}\) or \(e^{\beta_1}\) denotes the relative change in the odds that \(Y_i=1\). The odds that \(Y_i=1\) are \(\frac{\pi_i}{1-\pi_i}\).
Examples: challenger mouse
R Instructions
Console Help Command: ?glm()
To perform a logistic regression in R use the commands
YourGlmName This is some name you come up with that will become the R object that stores the results of your logistic regression glm() command. <- This is the “left arrow” assignment operator that stores the results of your glm() code into YourGlmName. glm( glm( is an R function that stands for “General Linear Model”. It works in a similar way that the lm( function works except that it requires a family= option to be specified at the end of the command. Y Y is your binary response variable. It must consist of only 0’s and 1’s. Since TRUE’s = 1’s and FALSE’s = 0’s in R, Y could be a logical statement like (Price > 100) or (Animal == “Cat”) if your Y-variable wasn’t currently coded as 0’s and 1’s. ~ The tilde symbol ~ is used to tell R that Y should be treated as a function of the explanatory variable X. X, X is the explanatory variable (typically quantitative) that will be used to explain the probability that the response variable Y is a 1. data = NameOfYourDataset,
NameOfYourDataset is the name of the dataset that contains Y and X. In other words, one column of your dataset would be called Y and another column would be called X. family=binomial) The family=binomial command tells the glm( function to perform a logistic regression. It turns out that glm can perform many different types of regressions, but we only study it as a tool to perform a logistic regression in this course.
summary(YourGlmName) The summary command allows you to print the results of your logistic regression that were previously saved in YourGlmName.
To check the goodness of fit of a logistic regression model when there are many replicated \(x\)-values use the command
pchisq( The pchisq command allows you to compute p-values from the chi-squared distribution. residual deviance, The residual deviance is shown at the bottom of the output of your summary(YourGlmName) and should be typed in here as a number like 25.3. df for residual deviance, The df for the residual deviance is also shown at the bottom of the output of your summary(YourGlmName). lower.tail=FALSE) This command ensures you find the probability of the chi-squared distribution being as extreme or more extreme than the observed value of residual deviance.
To check the goodness of fit of a logistic regression model where there are few or no any replicated \(x\)-values
library(ResourceSelection) This loads the ResourceSelection R package so that you can access the hoslem.test() function. You may need to run the code: install.packages(“ResourceSelection”) first.
hoslem.test( This R function performs the Hosmer-Lemeshow Goodness of Fit Test. See the “Explanation” file to learn about this test. YourGlmName YourGlmName is the name of your glm(…) code that you created previously. $y, ALWAYS type a “y” here. This gives you the actual binary (0,1) y-values of your logistic regression. The goodness of fit test will compare these actual values to your predicted probabilities for each value in order to see if the model is a “good fit.” YourGlmName YourGlmName is the name you used to save the results of your glm(…) code. $fitted, ALWAYS type “fitted” here. This gives you the fitted probabilities \(\pi_i\) of your logistic regression. g=10) The “g=10” is the default option for the value of g. The g is the number of groups to run the goodness of fit test on. Just leave it at 10 unless you are told to do otherwise. Ask your teacher for more information if you are interested.
Plot the Regression
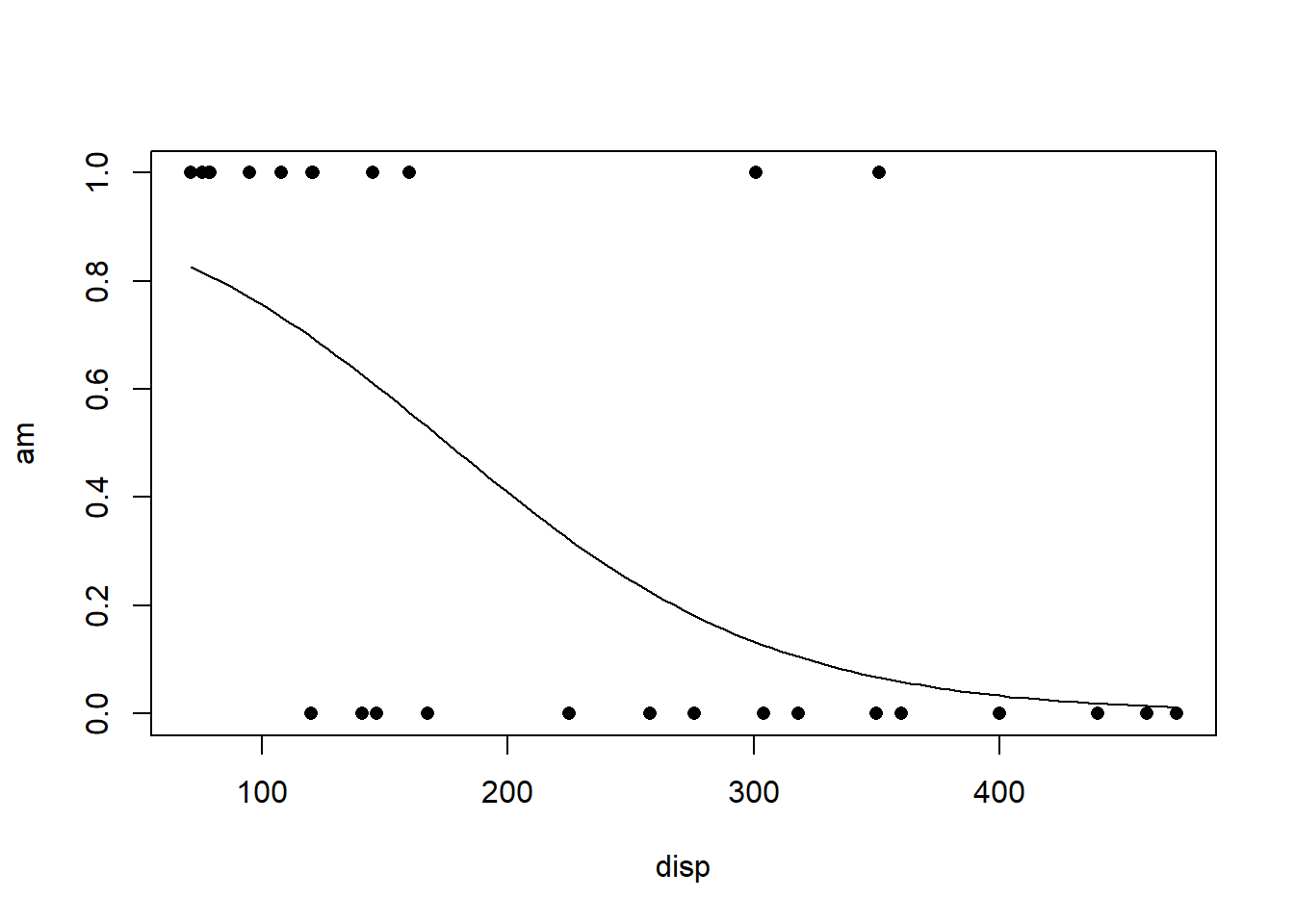
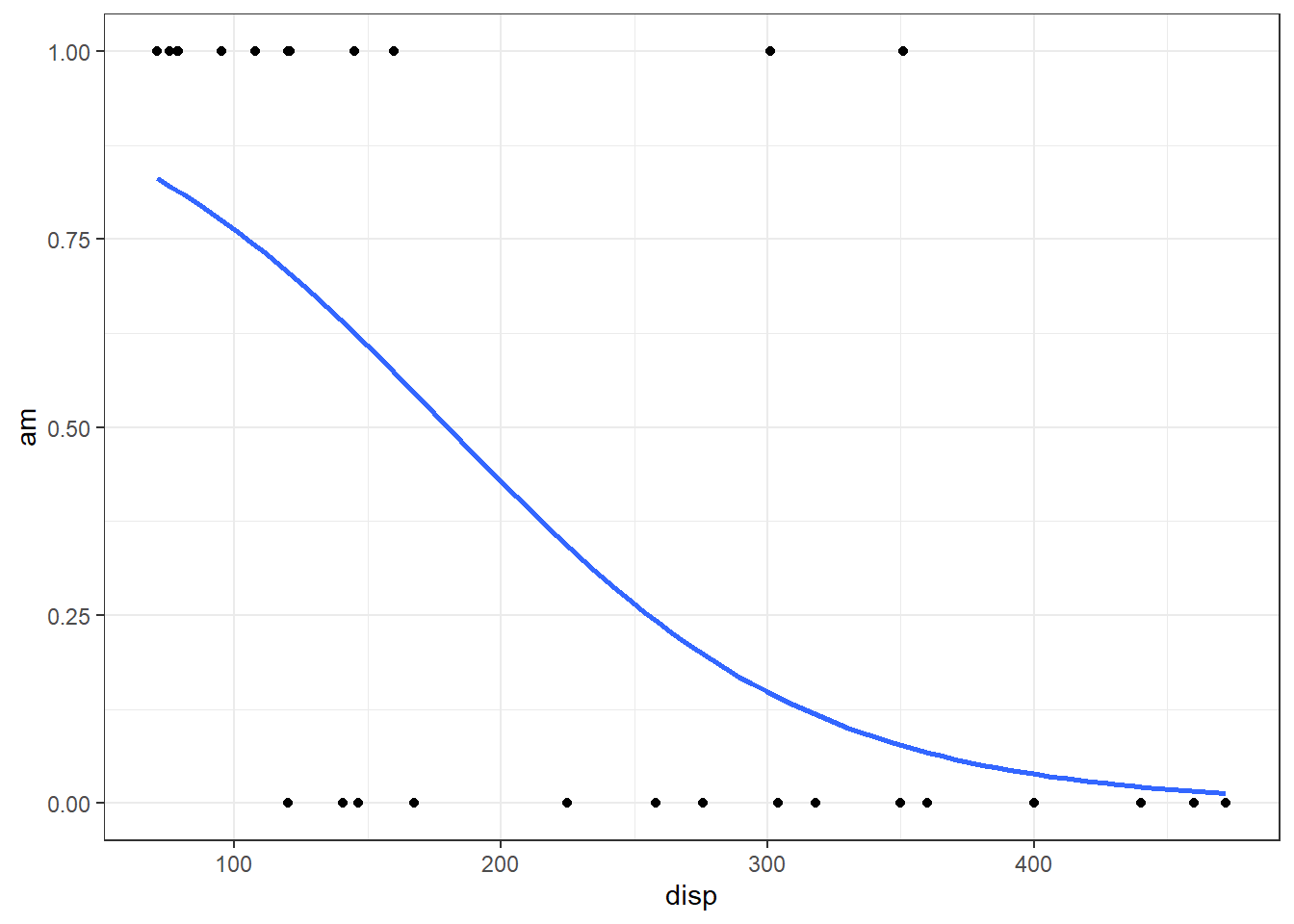
To predict the probability that \(Y_i=1\) for a given \(x\)-value, use the code
predict( The predict() function allows us to use the regression model that was obtained from glm() to predict the probability that \(Y_i = 1\) for a given \(X_i\). YourGlmName, YourGlmName is the name of the object you created when you performed your logistic regression using glm(). newdata = The newdata = command allows you to specify the x-values for which you want to obtain predicted probabilities that \(Y_i=1\). data.frame(xVariableName = someNumericValue), The xVariableName is the same one you used in your glm(y ~ x, …) statement for “x”. Input any desired value for the “someNumericValue” spot. Then, the predict code uses the logistic regression model equation to calculate a predicted probability that \(Y_i = 1\) for the given \(x_i\) value that you specify. type = “response”) The type = “response” options specifies that you want predicted probabilities. There are other options available. See ?predict.glm for details.
Explanation
Simple Logistic Regression is used when
- the response variable is binary \((Y_i=0\) or \(1)\), and
- there is a single explanatory variable \(X\) that is typically quantitative but could be qualitative (if \(X\) is binary or ordinal).
The Model
Since \(Y_i\) is binary (can only be 0 or 1) the model focuses on describing the probability that \(Y_i=1\) for a given scenario. The probability that \(Y_i = 1\) given the observed value of \(x_i\) is called \(\pi_i\) and is modeled by the equation
\[ P(Y_i = 1|\, x_i) = \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} = \pi_i \]
The assumption is that for certain values of \(X\) the probability that \(Y_i=1\) is higher than for other values of \(X\).
Interpretation
This model for \(\pi_i\) comes from modeling the log of the odds that \(Y_i=1\) using a linear regression, i.e., \[ \log\underbrace{\left(\frac{\pi_i}{1-\pi_i}\right)}_{\text{Odds for}\ Y_i=1} = \underbrace{\beta_0 + \beta_1 x_i}_{\text{linear regression}} \] Beginning to solve this equation for \(\pi_i\) leads to the intermediate, but important result that \[ \underbrace{\frac{\pi_i}{1-\pi_i}}_{\text{Odds for}\ Y_i=1} = e^{\overbrace{\beta_0 + \beta_1 x_i}^{\text{linear regression}}} = e^{\beta_0}e^{\beta_1 x_i} \] Thus, while the coefficients \(\beta_0\) and \(\beta_1\) are difficult to interpret directly, \(e^{\beta_0}\) and \(e^{\beta_1}\) have a valuable interpretation. The value of \(e^{\beta_0}\) is interpreted as the odds for \(Y_i=1\) when \(x_i = 0\). It may not be possible for a given model to have \(x_i=0\), in which case \(e^{\beta_0}\) has no interpretation. The value of \(e^{\beta_1}\) denotes the proportional change in the odds that \(Y_i=1\) for every one unit increase in \(x_i\).
Notice that solving the last equation for \(\pi_i\) results in the logistic regression model presented at the beginning of this page.
Hypothesis Testing
Similar to linear regression, the hypothesis that \[ H_0: \beta_1 = 0 \\ H_a: \beta_1 \neq 0 \] can be tested with a logistic regression. If \(\beta_1 = 0\), then there is no relationship between \(x_i\) and the log of the odds that \(Y_i = 1\). In other words, \(x_i\) is not useful in predicting the probability that \(Y_i = 1\). If \(\beta_1 \neq 0\), then there is information in \(x_i\) that can be utilized to predict the probability that \(Y_i = 1\), i.e., the logistic regression is meaningful.
Checking Model Assumptions
The model assumptions are not as clear in logistic regression as they are in linear regression. For our purposes we will focus only on considering the goodness of fit of the logistic regression model. If the model appears to fit the data well, then it will be assumed to be appropriate.
Deviance Goodness of Fit Test
If there are replicated values of each \(x_i\), then the deviance goodness of fit test tests the hypotheses \[ H_0: \pi_i = \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \] \[ H_a: \pi_i \neq \frac{e^{\beta_0 + \beta_1 x_i}}{1+e^{\beta_0 + \beta_1 x_i}} \]
Hosmer-Lemeshow Goodness of Fit Test
If there are very few or no replicated values of each \(x_i\), then the Hosmer-Lemeshow goodness of fit test can be used to test these same hypotheses. In each case, the null assumes that logistic regression is a good fit for the data while the alternative is that logistic regression is not a good fit.
Prediction
One of the great uses of Logistic Regression is that it provides an estimate of the probability that \(Y_i=1\) for a given value of \(x_i\). This probability is often referred to as the risk that \(Y_i=1\) for a certain individual. For example, if \(Y_i=1\) implies a person has a disease, then \(\pi_i=P(Y_i=1)\) represents the risk of individual \(i\) having the disease based on their value of \(x_i\), perhaps a measure of their cholesterol or some other predictor of the disease.
Multiple Logistic Regression Model
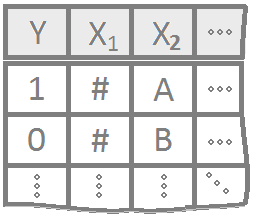
Logistic regression for multiple explanatory variables that can either be quantitative or qualitative or a mixture of the two.
Overview
The probability that \(Y_i = 1\) given the observed data \((x_{i1},\ldots,x_{ip})\) is called \(\pi_i\) and is modeled by the equation
\[ P(Y_i = 1|\, x_{i1},\ldots,x_{ip}) = \frac{e^{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip}}}{1+e^{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip} }} = \pi_i \]
The coefficents \(\beta_0,\beta_1,\ldots,\beta_p\) are difficult to interpret directly. Typically \(e^{\beta_k}\) for \(k=0,1,\ldots,p\) is interpreted instead. The value of \(e^{\beta_k}\) denotes the relative change in the odds that \(Y_i=1\). The odds that \(Y_i=1\) are \(\frac{\pi_i}{1-\pi_i}\).
Examples: GSS
R Instructions
Console Help Command: ?glm()
To perform a logistic regression in R use the commands
YourGlmName This is some name you come up with that will become the R object that stores the results of your logistic regression glm() command. <- This is the “left arrow” assignment operator that stores the results of your glm() code into YourGlmName. glm( glm( is an R function that stands for “General Linear Model”. It works in a similar way that the lm( function works except that it requires a family= option to be specified at the end of the command. Y Y is your binary response variable. It must consist of only 0’s and 1’s. Since TRUE’s = 1’s and FALSE’s = 0’s in R, Y could be a logical statement like (Price > 100) or (Animal == “Cat”) if your Y-variable wasn’t currently coded as 0’s and 1’s. ~ The tilde symbol ~ is used to tell R that Y should be treated as a function of the explanatory variable X. X1 X1 is the first explanatory variable (typically quantitative) that will be used to explain the probability that the response variable Y is a 1. * EXPLANATION X2 X2 is second the explanatory variable either quantitative or qualitative that will be used to explain the probability that the response variable Y is a 1. …, In theory, you could have many other explanatory variables, interaction terms, or even squared, cubed, or other transformations of terms added to this model. data = NameOfYourDataset,
NameOfYourDataset is the name of the dataset that contains Y and X. In other words, one column of your dataset would be called Y and another column would be called X. family=binomial) The family=binomial command tells the glm( function to perform a logistic regression. It turns out that glm can perform many different types of regressions, but we only study it as a tool to perform a logistic regression in this course.
summary(YourGlmName) The summary command allows you to print the results of your logistic regression that were previously saved in YourGlmName.
To check the goodness of fit of a logistic regression model when there are many replicated \(x\)-values use the command
pchisq( The pchisq command allows you to compute p-values from the chi-squared distribution. residual deviance, The residual deviance is shown at the bottom of the output of your summary(YourGlmName) and should be typed in here as a number like 25.3. df for residual deviance, The df for the residual deviance is also shown at the bottom of the output of your summary(YourGlmName). lower.tail=FALSE) This command ensures you find the probability of the chi-squared distribution being as extreme or more extreme than the observed value of residual deviance.
To check the goodness of fit of a logistic regression model where there are few or no any replicated \(x\)-values
library(ResourceSelection) This loads the ResourceSelection R package so that you can access the hoslem.test() function. You may need to run the code: install.packages(“ResourceSelection”) first.
hoslem.test( This R function performs the Hosmer-Lemeshow Goodness of Fit Test. See the “Explanation” file to learn about this test. YourGlmName$y, YourGlmName$y is the binary response variable of your logistic regression. YourGlmName$fitted) YourGlmName$fitted is the fitted probabilities \(\pi_i\) of your logistic regression.
To predict the probability that \(Y_i=1\) for a given \(x\)-value, use the code
predict( The predict() function allows us to use the regression model that was obtained from glm() to predict the probability that \(Y_i = 1\) for a given \(X_i\). YourGlmName, YourGlmName is the name of the object you created when you performed your logistic regression using glm(). newdata = The newdata = command allows you to specify the x-values for which you want to obtain predicted probabilities that \(Y_i=1\). NewDataFrame, Typically, NewDataFrame is created in real time using the data.frame( X1 = c(Value 1, Value 2, …), X2 = c(Value 1, Value 2, …), …) command. You should see the GSS example file for an example of how to use this function. type = “response”) The type = “response” options specifies that you want predicted probabilities. There are other options available. See ?predict.glm for details.
Plot the Regression
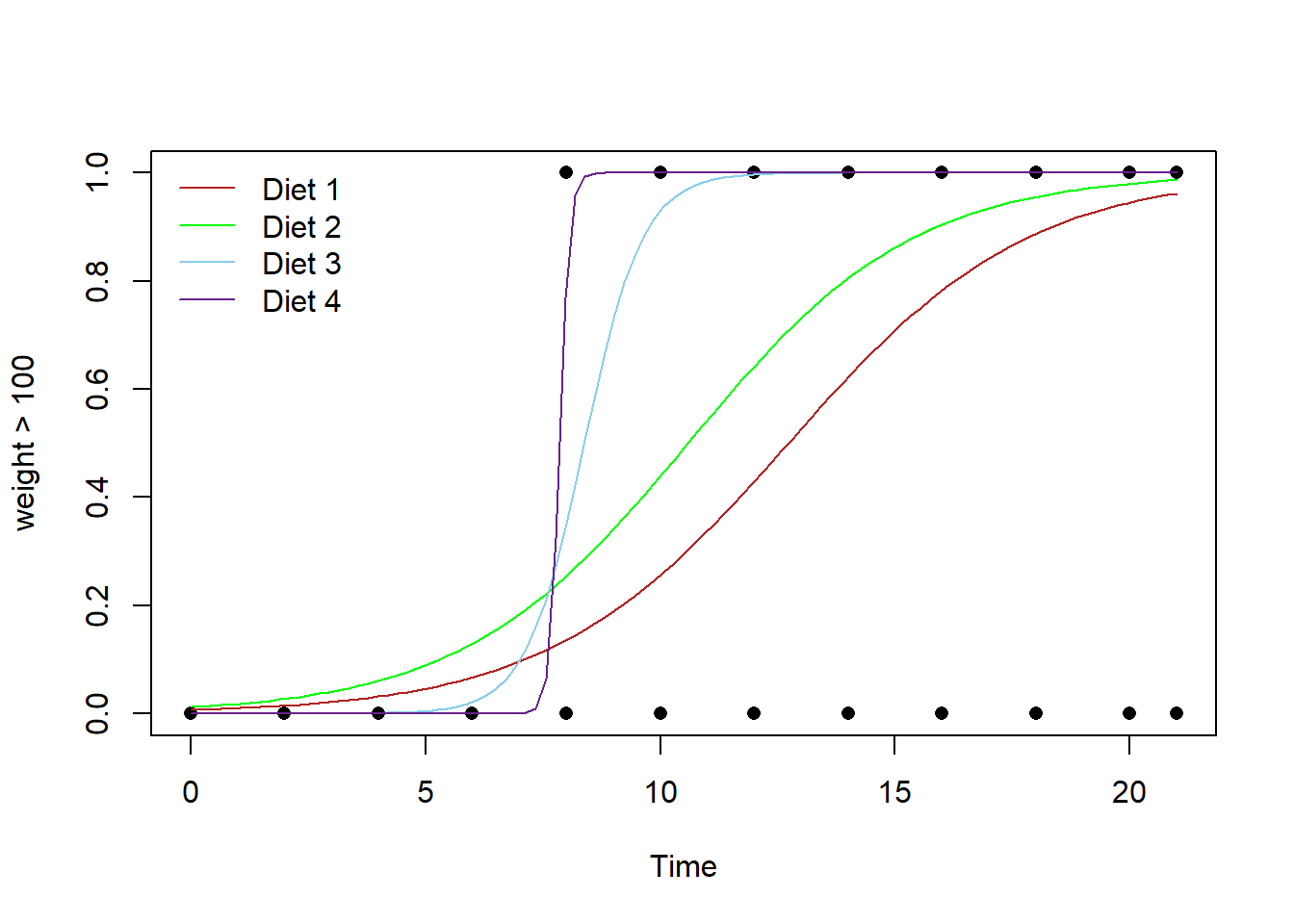
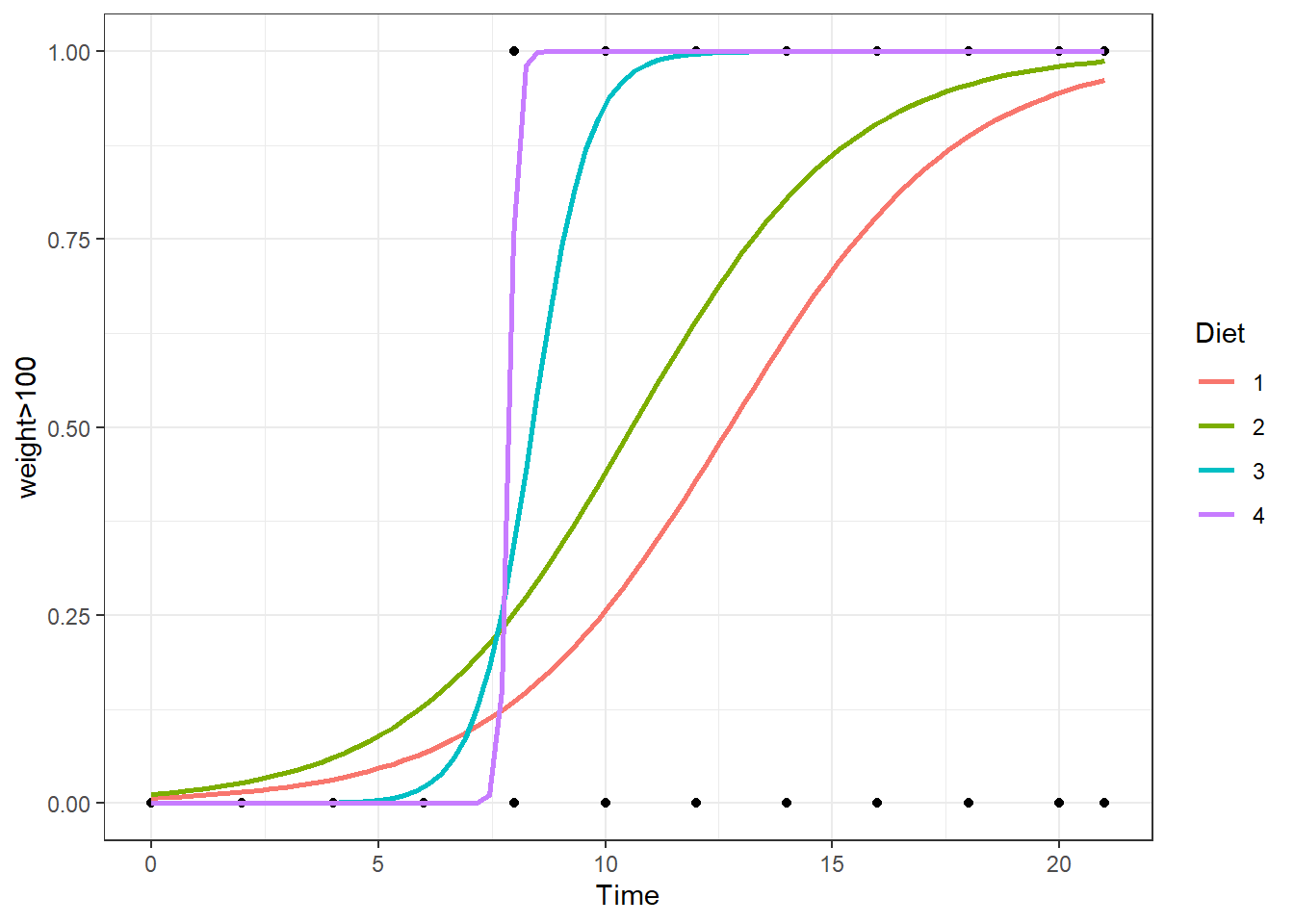
Explanation
Multiple Logistic Regression is used when
- the response variable is binary \((Y_i=0\) or \(1)\), and
- there are multiple explanatory variables \(X_1,\ldots,X_p\) that can be either quantitative or qualitative.
The Model
Very little changes in multiple logistic regression from Simple Logistic Regression. The probability that \(Y_i = 1\) given the observed data \((x_{i1},\ldots,x_{ip})\) is called \(\pi_i\) and is modeled by the expanded equation
\[ P(Y_i = 1|\, x_{i1},\ldots,x_{ip}) = \frac{e^{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip}}}{1+e^{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip} }} = \pi_i \]
The assumption is that for certain combinations of \(X_1,\ldots,X_p\) the probability that \(Y_i=1\) is higher than for other combinations.
Interpretation
The model for \(\pi_i\) comes from modeling the log of the odds that \(Y_i=1\) using a linear regression, i.e., \[ \log\underbrace{\left(\frac{\pi_i}{1-\pi_i}\right)}_{\text{Odds for}\ Y_i=1} = \underbrace{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip}}_{\text{linear regression}} \] Beginning to solve this equation for \(\pi_i\) leads to the intermediate, but important result that \[ \underbrace{\frac{\pi_i}{1-\pi_i}}_{\text{Odds for}\ Y_i=1} = e^{\overbrace{\beta_0 + \beta_1 x_{i1} + \ldots + \beta_p x_{ip}}^{\text{liear regression}}} = e^{\beta_0}e^{\beta_1 x_{i1}}\cdots e^{\beta_p x_{ip}} \] As in Simple Linear Regression, the values of \(e^{\beta_0}\), \(e^{\beta_1}\), \(\ldots\), \(e^{\beta_p}\) are interpreted as the proportional change in odds for \(Y_i=1\) when a given \(x\)-variable experiences a unit change, all other variables being held constant.
Checking the Model Assumptions
Diagnostics are the same in multiple logistic regression as they are in simple logistic regression.
Prediction
The idea behind prediction in multiple logistic regression is the same as in simple logistic regression. The only difference is that more than one explanatory variable is used to make the prediction of the risk that \(Y_i=1\).